GeMLoc - for people who like fast code and fast coding
GeMLoc - a generator of minimal localization. This is a tool for software developers in C/C++, which helps to localize application for using several languages with minimal cost of code execution. Tool works so that the process of coding suffers minimal cost compared to writing code without localization. By ideology this tool is an evolution of the concept of well-known library 'gettext' in the direction of accelerated performance and code writing.
Two examples demonstrate effectiveness of GeMLoc.

- That is in the process of writing code the programmer type "magic prefix" before the literal ('LC' in this example, while the other may be) and ... continues to type the code further, without being distracted by thought that this literal should be copied somewhere, the ID for it must be preserved, etc. In this example GeMLoc similar to 'gettext', where the programmer would have typed: _("my string") and would continue to write code without being distracted. Later, in any convenient day the programmer runs the script with a call GeMLoc, which automatically performs all "unskilled labour", looking for the literals marked with magic prefixes, replacing them, inserting the desired variable declaration, creation of the necessary files, etc.
Among other things, the script makes a substitution:

- Here LC__Hello_world is a variable of type const char * (as permitted const wchar_t *, and QString). That is, an array of characters (const char []) converted into a pointer to character (const char*). There is no function call which was carried out to search by ID, index, or string. There was a variable of type string and the variable of almost the same type was remained. With GeMLoc you can for all forget about doubts: "If application will slow down on the large number of strings? How about optimization?" There do not need to optimize, because nothing to optimize.
GeMLoc has many useful features. Here are two for example: he tells the programmer which strings are no longer needed (the guarantee that the outdated rubbish will not be included to release) and the tells to translator how many strings and which languages need to be translated.
GeMLoc is "friendly" with ASCII, UTF-8, Unicode, Qt, RC, Windows and Unux.
What's the catch?
From the original description it would seem that so well does not happen, there must be some trick. Indeed, there is a problem, rather, a psychological nature: the fact that Gemlok modifying the source code. Scared? I know from experience: Some scary. Therefore, it's need explanation.
Gemlok working with sources on a principle "do not ask - do not go". As long as you do not put "magic prefix" before any string the tool will change nothing in the source file.
The probability of data loss when writing the file is not larger than a similar accident, while maintaining source code in the editor. When GeMLoc modify the source code it first creates a temporary file, which is written with a new version of the text, and only after successful completion of the writing GeMLoc replaces current file with temporary (by renaming). Replacing by renaming takes place almost instantaneously so that source code damage can be only on power failure, which occurred just at this millisecond.
Especially for programmers who forget to save your data, GeMLoc has several commands rollback, backup-and recovery as well.
Finally, you shouls understand that it is modified in the source. There is not much really, just two things. The first is labeled "magic prefix" literals are replaced by variable names. For example instead of the LC "Hello, world!" after treatment GeMLoc-th LC__Hello_world appears. Second thing this variable LC__Hello_world need to be declared somewhere so at the beginning of the file after the traditional "comments header" #ifdef and #include GeMLoc looking for the right place to insert declaracion extern const char * LC__Hello_world;. That's all. If interested in the details, then read the manual on.
Here is a simple example that demonstrates GeMLoc.
GeMLoc can generate examples of itself.
Enter into some empty folder and run GeMLoc with the following parameters:
Is is recommended write this call as .bat file or script for daily work since this call
will be enough for 100% of the cases.
The folder should now contain 8 new files:
Now compile the program. For Visual Studio:
example.exe. must be created. Run it by passing the name of a loadable dictionary
through the commandline:
The program should output:
Now look in the file rus.loc. This is a text dictionary for the human translator.
Ignore /!TRANSLATE/! marks. Do not touch any before sign of equality they are string IDs.
But after '=' replace text with a string of another language. Look out!
For the Russian language in Windows, use the DOS-866 encoding, because it is a console application.
Now again do the same command:
And run:
The first call outputs the same strings in English, and second then outputs the string that
you entered in rus.loc in a different language. If, of course, the console itself is set up properly,
use the right encoding and the font with necessary characters.
Now look at the contents of the file example.cpp. You will see where the variables
like LC__Translate_this_first_string. So look the localized literals are already
after localization.
This example uses the command -auto. It is the main "workhorse"
and is essentially a macro that calls the other commands. This example
may be decomposed into the following calls:
I advise you to delete all the generated files and execute these commands to see what happens at each step.
This section, I strongly recommend those who love to ask questions like "why done so, not so?",
"why do we need it?", "but why it's better?". If these questions you do not mind, you
can skip the section.
For many C/C++ projects, it is necessary to choose the language, and depending on the language
display different text strings. Strings that are loaded from different files
data bit of fuss: just created versions of these files for each language. Primary
amount of work associated with the strings that are written in the source code in the form of so-called.
literals, in other words, in quotation marks. In fact, there is a task for these strings to be loaded
from somewhere too.
You can, of course, do not use literals at all, but load them from the beginning of program development.
Prudent programmers each accident "OK", "Yes", "No" form as a certain
function calls, which should load the the string depending on the current language, and creates an
external file, which contains string themselves for at least one language.
What good is this way it is clear: the program is immediately ready for translation into different languages.
But for this to be paid longer-term development of the first version of the
product. Plain developer typed in the program text "Yes"
and will continue vigorously to print the code on. The prudent developer would write something like
loadString(IDS_YES) and then switch to a file of identifiers, where typed
something like IDS_YES = 123, then switch to a file of strings, where typed
something like <localization id="IDS_YES" lang="English" value="Yes">,
then return to the source code. Even if we use all sorts of Copy/Paste,
still the process is slowed down because of the need to switch between files.
Additionally, if identifiers are formed as a header file, which is included to many sources,
each time after adding new string is needed to massive recompilation of the project.
But time goes on. Time is money of the employer. Greed puts pressure on the brain of the employer, the
employer presses on the brain of the project manager, and the project manager puts pressure on the
brain of programmers: make faster first version without localizations, we will make them later.
Is this requirement from the standpoint of universal justice the question, so to speak, philosophical,
you can of course, to debate topic and so spend a little more time (that is the money of the employer
and healthy brain of the project manager).
Anyway, in many cases there is a task of optimizing the development process.
To understand what can be improved, we must see what we have. Let's start by
consider not just one of the most advanced localization systems, but the ones
that programmers often make by yourself. The typical localization system can
consist of 3-4 parts:
To get the localizaed string, must somehow specify which of the strings to get, respectively
need the string ID. In the worst case ID is just a number, so to say "magic number".
Once the programmer learns about the problems of "magic numbers", he replaces the numbers
by the constant identifiers (#define, enum or const). Usually all these constants are
written in a single header file.
This how is done Microsoft resource files. The project for Visual Studio there is usually
has a file with the extension .rh containing all of the integer resource identifiers,
including identifiers of strings, and there is file with the extension .rc, which
stores the strings themselves with references to the corresponding identifiers.
When you compile a project a file with the extension .res is created
from .rc/.rh and at linking time is added to the executable file .exe.
During the execution the program accesses to the loader, which returns the string
by an integer identifier.
The idea to store all the string IDs into a single file is partially the right. It
guarantees that there will not random duplicates. However this header file must
be included to many sources of the project, and the slightest change in the
list of identifiers leads to a mass recompilation of the project.
Once the programmer is bored by many recompilings after each tiny change, he begins
think, is it possible to get rid of the header file at all? And a natural idea is appeared
let's IDs are strings? The next idea let's IDs be original literal in English?
When call the loader programmer given an English string to it; if the current language
is English, the loader returns the same string, and if not English,
it uses this string as the key to find the translation into another language.
This handy and clear: to write getLocalizedString("Hello, world!")
instead getLocalizedString(IDS_HWRLD). Immediately clear what the
text will be returned, and no need to invent an identifier.
Moreover, in the loader you can register the condition that if the string
is not found, then return the ID. This immediately solves problem with switching
between files when typing source code. You can fill the code, without being
distracted, and everything will work, though only in English but other
languages can be added sometime later.
Now if loader call take the form of an identifier of minimum length (one character, for example,
a single underscore character), then it will be enough write _("Yes"). This is only three characters
longer than absolutely without localization. As it turns gettext library and others like it.
All is good, but old-school programmers gnaw doubt, they are used to ID
should be integers if possible, since the search on the string is slower.
It can be optimized, you can create a hash or the search tree, but no
matter how optimized, it is still slower than the search for an integer
identifier, which can just be an index into an array of strings.
Programmers of new school knows no such doubts either at all, or as long as
write any loop, where access to the loader many thousand times. Then they
have to optimize the program. In most cases, it is easy to do, refer to the
loader should be moved before the body of loop, the results should be stored in
variables, and inside the loop access to these variables, without having to
call functions.
Resource files in Microsoft came at a time when computers were much slower
so that the search for a integer ID seemed the most natural solution. Now that
power technology has improved, in most cases relatively slow search by string
is good enough too. In most cases is good, but it is sometimes necessary
to optimize. It turns out that if you make a search by an integer, then you will
lost the time with recompiling and switching between files during the typing.
And if you make a search by an string then sometimes you will spend time to optimize.
But there is a third way that combines the advantages of the previous two,
but do not inherits their shortcomings. It is the way, which is
implemented in GeMLoc. This way uses the fact that any program on the C/C++
was initially already has a string IDs (the names of variables), and a
search for IDs (the process of "linking" when building the executable).
To clarify the terms:
If I define a string in a source file as a const char *myString = "Hello, world!",
and in other place will declare its as extern const char *myString and
access to it as myString, then the compiler finds the string identifier
myString and substitute the desired address. Switching to a different language
is achieved by "switching" pointer myString to the address in memory where the
string is loaded for a different language.
Technologically, we have the following. There is a module with a particular string (say, somefile.cpp).
For each localization variable type of const char * there are allocated 4 bytes (or 8) in the static data.
Further, there is a file or files that contain the string content for different languages (dictionaries).
When the selected language, the loader allocates a buffer in the heap and loads the strings.
After that, loader write to a variable of type const char * the address in that buffer.
In other modules variable is declared as extern. Any acess to the variable will return
the text in the target language.
So far, so good in terms of speed of execution of the program, but switches between files stays.
After creation a string you must go to the file somefile.cpp, copy string, then save somewhere
literal to be loaded, then return to the source file, declare the variable as extern and
finally, replace literal with the variable name.
The trick is that all of these steps can be automated. To do this, define some
"magic prefix" It is the short identifier for example, LC or LK.
The compiler to ignore it, this identifier is defined as an empty macro, ie:
Further, a programmer in its source file (say, somefile.cpp) writes: LC "Hello, world!".
Because the LC is defined as an empty macro, from the perspective of a compiler is
like, what to write "Hello, world!" without the prefix. As a result, the program
will be compiled as usual.
When you are running GeMLoc, he will do the following: "invent" a suitable identifier for
a variable, say, LC__Hello_world, insert its definition as a const char * LC__Hello_world;
to special file, write extern const char * LC__Hello_world; declaration
to somefile.cpp and replace prefixed literal LC"Hello world" with
variable name LC__Hello_world. From the perspective of a compiler type
const char [] was replaced by const char *, that 99% of cases lead to
successfully recompiled and proper running applicaion. In the remaining 1%
cases, the localization failed (any, not only through GeMLoc) and code should be
modified (see Appendix 3).
That's the basic principle. All other features GeMLoc make implementation of this
principle more convenient.
This and all subsequent topics are divided into two parts: the "Summary" and "Details".
Heavey "Details" part contain full relevant information and the "Summary" part contains
short manual. If you immediately understood the "Summary" part then you may
pass "Details" until you need some subtleties.
Summary_____\
Below is a simplified pattern of localization with GeMLoc.
Details____ \
The scheme assumes that the project has three development commands, each responsible
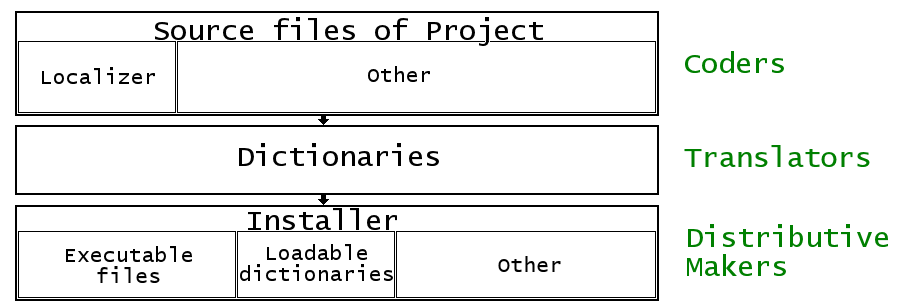
for his part. Of course, a little project may be handled by signle person.
The first group, designated as "Coders" creates the main application based on "sources"
that is, the source files of the project, which includes in our case
C/C++ modules with extensions .c, .cpp and header files with the extensions .h, .hpp.
GeMLoc adds some its files to these and updates them in automatic mode.
In this scheme created files marked as "Localizer".
The second group, designated as "Translators" engaged in translation dictionaries
to different languages. There may be people with a distant view of programming
as linguists, philologists. GeMLoc creates and updates the dictionaries in the
automatic mode, and provides suitable formats for processing in text editor
and intelligible to the layperson.
The third group, designated as the "Distributive Makers" is engaged in writing
the installer. For these developers GeMLoc creates loadable dictionaries on
the basis of text dictionaries, translators have worked with. Loadable dictionaries
have "unreadable" ("binary") format, which is optimized for fast loading. They should
be part of the installed program and will be loaded at run-time by loader which
code is included in the box "Localizer" in the upper part of the scheme.
Next is a link to a large and detailed variant of first scheme.
I recommend to open this picture in a separate window, and periodically turning
to it in the process of further reading. Later that sceme may be enough as
reminder instead of reading all this text.
Summary_____\
You must select a short identifier (like LC) and define it as an empty
#define and use it as mark for literals to be localized of the form
"...", L "...", _T ("..."), _TEXT ("...") either as a prefix in
front LC "...", or in the style of function call LC ("...").
Details____ \
You must select the "magic prefix". This is ID which will mark the strings,
which can be localized, and it helps to identify other names associated with
the GeMLoc.
For the "magic prefix" there are the following limitations:
I recommend using the two-letter prefix of LC for the main program and
if libraries have a separate dictionaries then for them to use 3 or 4-letter prefixes
such as LCX, LCZM, etc. Also, perhaps, you will enjoy a prefix LK, which
is easier to type by two near placed keys.
Further, the magic prefix must be specified as an empty macro, for example:
This macro should be in a file that is included everywhere can be a string to be localized.
The natural solution is add the macro to the precompiled header. Prefix should be
added only once, and does not changed (or changed very infrequently), so that
additional recompilation are not problem.
Now you need to use the magic prefix to mark some literals in the program.
Allowed to mark the usual (char) literals, unicode-literals (wchar_t), marked
with the prefix L, and literals framed by macro _T, _TEXT, for example:
Note that in the first case, a space before the string is optional, it's a little
saves you time during typing the text.
It also allowed a longer format of the mark with brackets:
This option is on the case, if you want to program some trick, defining LC
not as an empty macro, as well as a macro with parameters, or even function.
Also it is allowed (but not recommended for initial localization of project)
yet longer format with all translations:
If translations contains non-ASCII characters (for example Russian letters)
then use the same encoding as you want to load on runtime (UTF-8 is recommended).
If you are not dealing with a newly created project, and you already have
a project with a large number of literals, the setting marks by hand can
be time consuming. GeMLoc can automate much of this work, as will be
discussed in the sections devoted to the localization of the "old" projects.
Summary_____\
You must select one of the types of localization: const char * (the default), const wchar_t *
(option -wc), or QString (option -q8/q16, if implemented function QString::fromUtf8/16 respectively).
Details____ \
GeMLoc provides four different types of localization, depending on what
string in the program you are using most often.
The default option is expected to -cc, that is the loadable dictionary will contain
char-s, and they will be pointed by variables of type const char *.
Character encoding is unimportant in this case. What 8-bit characters are in the dictionary
the same will be loaded into memory. The same characters should be encoded in the text
dictionaries (for human-translator). In particular, you can use UTF-8. In last case you
can use option -utf8 to force check characters in dictionary.
If you specify the option -wc, a text dictionary must always be encoded in
UTF-8 (checking option -utf8 is assumed by default). In the loadable dictionary strings are in UTF-16 and after loading
they will be pointed by variables of type const wchar_t *. This option is intended
only for those systems where the type wchar_t is 16-bit, little-endian (as in Windows).
If you are working with library Qt, you may find it convenient to use strings like
QString. Then the text dictionary should always be in UTF-8, and the loadable dictionary
will either be in UTF-8 or UTF-16. It's all depends on the version of Qt, which you
compile and use. Check if it has a function of QString::fromUtf8, you must use UTF-8
and the corresponding option -q8. And if there is a function QString::fromUtf16, use
option -q16. And if there is both then use as you like (note that
dictionaries with the option -q8, will likely have a smaller size, and
dictionaries with the option -q16, will likely to be slightly faster to load).
Depending on the type of localization GeMLoc generates the appropriate code. If
different parts of the programs use different types of strings, you may
use several dictionaries independently.
That they did not mix with each other, just use different prefixes.
You can even apply different localization in a single file, using
the different string prefixes.
Summary_____\
All commands of GeMLoc have the same syntax:
Details____ \
Options always begin with a dash. The command is always present, and also begins with a dash.
There is a commands: -auto, -bin, -cpp, -commit, -edit, -example, -help, -loader, -mark,
-prefix, -restore, -rollback, -test, -unmark. Next, you may need
"magic prefix", sometimes two prefixes (always without the dashes).
Next is <list of sources> are arguments that always begin with the characters
-, + or =. The first argument, starting from another symbol is first
of the final part: <other files>.
For example:
Here -backup, -wc are options, -edit is a command, LC is a prefix. Next <list of source>
are all the arguments, starting with the symbols +, - and =. A sign of the end of the list of sources is the
first argument that begins not with +, - and =. This is done for consistency and to avoid accident confusion
with another source file. In this example, english.txt and russia.txt are not part of the list of
sources, and are additional files (dictionaries).
Summary_____\
List of sources is formed by a series of arguments:
Details____ \
Usually C/C++ linker works with several source files. List of these files are prepared in
one way or another in the makefile, or stored separately as a "project file".
GeMLoc also works with list o fsources instead of one. This reduces the time of the
utility execution, because it do not have to repeatedly download itself and can
update the dictionary once. And most importantly it allows you to determine which
strings are no longer used in the program.
Source files to include to the project in the language C/C++ it usually files
with extensions .cpp/.c/.h/.hpp.
Consider the example:
List of the sources begins with the argument +main.cpp and ends with the argument =save.lst (inclusive).
All arguments with '+' added files to the list and arguments with '-' exclude files from the list. Argument
with equality writes down the resulting list to a file.
Argument +main.cpp adds a file 'main.cpp' to the list. In principle, this may be enough, but to list all files
of a large project is too boring.
Argument +mylib adds to the list of all files in the folder mylib. But, what if in this folder also
contains object files? Then, the argument -mylib/*.obj will exclude from the already created a list of files
with extension .obj, located in the folder mylib. But what if the sources are not only in the specified folder,
but also in its subdirectories? For this case, is a construction with two pluses: ++external/*.cpp, it says
GeMLoc process all subdirectories recursively from external. Similarly, the argument with two
'-' recursively exclude files.
For programmers who use the Visual Studio life is simple: GeMLoc understands the contents of the project files
.vcproj and .vcxproj. Just write +proj.vcxproj, to include a list of all source files in project proj.vcxproj.
Moreover, if your project for the Debug configuration includes some files, but for Release includes other
(i.e., some files depending on the configuration is marked as "Exclude from Build"), you can
put the files to the list selectively by specifying a configuration option -config, for example:
Note: If the project uses relative paths to files, then GeMLoc will use them from the folder where it is
stored the project file.
For users of other frameworks may be useful file in which the sources are listed. In the example above, the
argument implies a +addon.lst file. Sources should be listed one per string. If the paths are not
absolute they will be used from the folder where the list file stored.
Finally, one day you may be want store a list of sources. In the example, it makes the argument =save.lst.
Summary_____\
Dictionary is a central concept in GeMLoc. There are text dictionaries (with the extension .txt or .loc)
and loadable dictionaries, which have a binary format and extension .bin or.lng. By default, a
"dictionary" here refers to a text dictionary.
Dictionaries contain the identifiers of the strings and content of strings. Also, dictionaries can
contain comments. For example:
One dictionary corresponds to a single language. Dictionary of the English tend to "primary" and the rest are "secondary".
One primary and several secondary dictionaries form a set of dictionaries. A software product may use multiple
sets of dictionaries. For example, one for the DLL, the second and third for the two static libraries and fourth
for the main program. It is very desirable (to avoid naming conflicts during link) for different sets of dictionaries
use different "magic prefix".
The primary text dictionary is created by commands -auto or -edit based on the source files.
Secondary text dictionaries are created by the same command based on the primary dictionary.
Loadable dictionaries are created by commands -auto or -bin based on text dictionaries.
GeMLoc allows two formats for text dictionaries. The first is "escape-format" convenient for programmers,
because use syntax of C/C++ strings with escape-character '\'. The second is "raw-format" is intended
for linguists and philologists, who may be know nothing about escape-codes.
Details____ \
Escape-format contains strings as follows:
id = is the name of a string variable without prefix. If a variable is
LC__Hello_world, the identifier in the dictionary must be Hello_world.
value = corresponds to the contents of the string. Syntax is like for C-literal, except for
the following points:
As in the string C/C++ literals allowed to break into multiple strings with \ at the end, for example:
Raw-format contains strings as follows:
id = the same identifier as in the escape-format.
value = the contents of the string without any codes. Transitions to the next string are treated as
newline characters except for the newline after the id, and before /END/.
/END/ = indicator of the end of the string.
Raw-format has several serious drawbacks: it is difficult to correctly enter
characters with codes less than 32, it is unrealistic to keep the difference
between '\n', and a pair of '\r\n', you can not use the sequence /END/ as
part of the string. Therefore, raw-format recommended for use only in
case of close contacts of any kind with deep non-technician persons, for who
can not explain the difference between '\n', and '\r\n' and who at all times
strive to save a text file in Microsoft Word .doc format.
In these circumstances, we should give a file in the raw-format, and later
may be convert it to escape-format and adjust special characters.
About comments
Dictionary file can contain three comments on the following string:
1. Comment /!REMOVE!/ inserted by GeMLoc as an indicator that the literal
not used in the program. GeMLoc will not remove this literal as well
(you could just not list the file where the literal is still used, and
you can temporarily comment out a piece of code where it is found that a literal).
Delete unused strings of the dictionary can be either manually or by adding the
option -remove to the commands or -auto. While still in the dictionary
such comments, GeMLoc will remind you of their existence with messages like:
2. Comment /!TRANSLATE!/ inserted by GeMLoc as an indicator
that the literal has been copied from the primary dictionary. This is a reminder for the translator,
that the string is in English, and it should be translated into the language, which is associated
with this dictionary. You will need to remove these marks when translate the string.
While in the dictionary are such notes, GeMLoc will remind you of their existence
with messages like:
3. Other comments of the form /!some text!/. Such comments
simply stored as is.
About the duplicates
Occasionally it may be a situation that some text in the program should look the same
in English, but in different ways in a different language. This is called a duplicate.
The reverse situation (in different ways in English, the same in another language) is not
considered a duplicate and does not require any special actions.
You can create duplicates when edit the primary dictionary by text editor. For example,
you have a string that is in English in the two cases is written as a "row", but in Russian
the first case as a "строка", while the second as the "ряд". By scanning files with English
literal GeMLoc will create a single variable LC__row, and one entry add to the dictionary:
To now create a duplicate, must be in the same dictionary to have another string with the same content, but
other identifier:
Note: If the ID row__0 is already exists, use the ID row__1, if such
exists too, use row__2, etc.
After that, write to the Russian dictionary different values of strings:
Now if GeMLoc meet LC"row", in the source code it warns that it can not determine
what variable should be used: LC__row or LC__row__0. You will have to
replace this string in one of the variables manually (and extern-declaration GeMLoc will add
himself at next call).
As a result of a series of such modifications may create a situation where the two dictionary entries
has the same string content not only for English, but also for all other languages. This is called
a full duplicate. Most likely, you'll want to get rid of such extra copies.
GeMLoc can do this automatically if you specify the option -remdups in a command -auto.
Then the second of two identical variables will be removed from the sources by replacing the first,
therefore no longer be used and will be marked with the comment /!REMOVE!/. If at the same time
specify the option -remove, it will be immediately removed from the dictionary.
About string order
During ditionary generation with integer identifiers GeMLoc inserts
integer values after identifiers (comma separated). This done to preserve most of the
integer identifiers the same after insert/remove/update of strings and decrease number
of updated sources.
Summary_____\
A set of commands with the option -backup saves copies of all modified files with the extensions .h.bak, .cpp.bak, etc.
The first command with option -backup defines a checkpoint for the command -restore, which restore
all the files to the state before the checkpoint. You can define a new checkpoint by a command -commit,
or simply by delete all .bak-files.
Details____ \
Some programmers accustomed to that source files changed either by a man or generated by some tool
and people do not change it. In contrast GeMLoc makes minor changes to the "human" sources, and
it can upset some programmers. Of course, such a scheme of work uses more than one only GeMLoc
any system of automatic "refactoring" do the same, but referred type of programmiers may fear,
those systems, too. Instead of persuading them to get rid of the paranoia, I chose to add
in GeMLoc automatic backup and recovery.
The same feature will be useful for other types of programmers who are too risky and begin to experiment
with a large "live" project, not really knowing what they do and too lazy to create a backup. For these
will be useful to know about he possibility include to the command string only one option, and insure
themselves from problems. And for very, very lazy ones there are some additional possibilities
but later.
If any command has -backup option then before change every file GeMLoc will first be established
a copy with extension .bak. For example, for the file main.cpp will be created copy main.cpp.bak.
Note: extension is double, to avoid potential conflicts with text editors, who also likes to create
backup Files, but with a single extension (main.bak).
Example:
GeMLoc make little changes in sources, but these "little" can occur with many files in a single pass.
You can rollback number of minor changes by hand, but why bother when you need not? It's enough to add the
command option -backup. It is strongly recommended to do this every time you are going to
to put some kind of "experiment" with GeMLoc, and poorly understand what will happen next.
If something goes wrong, you can rollback the changes by a command -restore. It should list all the
same files as the command that caused the problem. Just remove the argument that specifies the prefix
and the option -backup:
This will restore all changed files listed in the project file proj.vcxproj ansd file english.txt, if it was changed.
If you wish, you can specify not all parameters from the previous command, znd rollback the changes not for all
files, but only some.
Note: -restore is a command, and -backup is an option that accompanies any command e.g.
-edit, -mark, -auto.
If you give a series of commands with the option -backup, then GeMLoc acts as if the first command with this option
set a kind of "control point" (checkpoint), which marks a time when everything must be rolled back. That is, after several
commands with the option -backup command -restore rollback these files up to the state that they
had before the first command with option -backup. Implementation is simple: if GeMLoc sees that the corresponding
.bak file already exists, it does not trying to create a new one.
On the one hand, it is convenient: it is possible for a long time experiment, not thinking about the
consequences, giving the command after command, and then return everything back with one step. But on
the other hand, if the experiments are successfully completed, it is necessary do not forget delete all
.bak files, or the next failed experiment will make rollback too far.
Delete all .bak files using the command -commit. It has the same format as the -restore:
If you find that easier to remove .bak-files by any file manager or shell command then do it. Command
-commit is just for completeness and for the purpose of automation.
To make it work properly, follow the principle: after all experiments with the option -backup
do either command -restore, or a command -commit. Both remove .bak files, but only the
second simply deletes then, and first make renaming.
Summary_____\
Details____ \
During preparation of the "old" project to localize with GeMLoc after choosing the "magic prefix" and
the list of sources the next step is placement prefixes in the sources. To make the process faster, you
can do it in a semiautomatic mode. To do this use command -mark. Its format is:
gemloc <options> -mark <prefix> <list of sources>
This command insert a prefix before all literals that seem suitable for localization.
The principle of the automatic insertion is the following:
Automatic placement is not able to guess exactly what should be localized. So
after it, in any case you have to perform a prefix search for all files with
the command grep, of "Find in Files" dialog or with similar instrument.
Look at the results and remove unnecessary prefixes. For example, it is not need
to localize name of the operating system "Windows", the company "Intel" or
computer abbreviation "HTTP".
By default, the prefixes are inserted in the form of LC"...". The -() option
tells use instead the scheme: LC("...").
If you do not have backup, but you want to roll back the changes, try the command:
gemloc <options> -unmark <prefix> <list of sources>
But keep in mind that such a rollback is not always one-one: there may be extra spaces.
For example, if the string was marking up LOGO"aaa", after the marking will be:
LOGO LC"aaa", but after removing the marks will LOGO "aaa" (with a space).
The fact that the string LOGO "aaa" (with a space) after marking is also becoming
in LOGO LC"aaa". In general, the command -unmark is not intended for an ideal
rollback as an option -backup.
If you decide to change the prefix, use the command:
gemloc <options> -prefix <old prefix> <new prefix> <list of sources>
This command will replace prefixes marking literals and variables that were set
in place of literals. After this you should change the #define prefix (where you have it
defined) and generate new strings definitions (see command -cpp) and adjust
name of the variable of loadable dictionary parameters (see command -example).
Summary_____\
Generate code of loader with command:
gemloc <options> -loader <cpp-file> <h-file>
and add the two resulting files to the project.
Details____ \
Loader is a module that will load at runtime loadable dictionaries in different languages.
And although there are dictionaries have not yet, the loader is generated before for
successful compilation of the project. Total GeMLoc generates 4 source code files,
of which 3 must be inserted to the project. Of these, 2 belong to loader (one cpp-file
and a header h-file). If an application consists of several libraries, these two
files can be generated only once and inserted to one of the libraries, and other only
use that module.
The loader looks like a class in which, apart from the constructor and destructor, is
the only function of load. The name of the class by default is Localizer,
but may be changed.
The loader is designed as two sources, which should be added to program
or library, rather than as a compiled library. This allows you to use the same
source code for a variety of options and compilers. Format of generation command:
gemloc <options> -loader <cpp-file> <h-file>...
The code generator offers many different options that allow you to create a
one or another version of the loader. A complete list of options is shown here.
Summary_____\
Adjust the sources by running:
gemloc <options> -edit <prefix> <list of sources> <primary dictionary file> <secondary dictionary file>
- Strings marked by a "magic prefix" will be moved to the dictionaries, and in their place
appear the names of string variables.
Details____ \
Note. Command -edit is intended for learning this technology step by step.
For daily work you should use -auto command instead because it makes job
of -edit, -cpp and -bin with single call.
-edit is a main command, which makes changes in source files.
First of all, the command scans the sources for literals marked
with "magic prefix". Content of literals is stored to the dictionaries
whose must have the extensions .txt or .loc. When the dictionaries are saved
successfully, sources changes starts.
The first change is the replacement of literals, marked with "magic prefix"
with the names of variables. For example:
Here LC__Hello_world and LC__my_string are string variables
of type const char *, const wchar_t * or a QString.
To learn how variable names are generated, see here.
The second change is GeMLoc inserts the block of 'extern'-declarations for
those variables. This might include:
To learn how a place to insert the block is finding, see here.
The replacement may produce errors of linking and compiling. Errors
if linking are normal, because string variables are declared
but not defined. Definitions will be added in the next step
(see next section). Regarding the compilation errors, then, in theory,
they should not occur if you have prepared a program to localization correctly.
If not, read the analysis of the most usual errors here.
In the examples above only one line for the primary dictionary (usually English) is specified.
But you can specify all translations immediately like this:
LC("Hello, world!", "Здравствуй, мир!")
The number of translations must be equal to the number of dictionaries in the command.
If translation contains non-ASCII characters like Russian letters here then source
file must be in the same encoding as strings you want load on run-time (UTF-8 is recommended).
Complex syntax may be convenient if you want add single literal to already localized and translated project.
In this case you save some time by avoiding opening of dictionary files and search literals in them.
A more "standard" method is to type only English literals and translate them later by editing of dictionary
files. This method is better if you writing new module with many new literals.
The first dictionary is "primary" and the rest are "secondary". Secondary dictionaries forced
to the same set of strings, as in the primary dictionary. Extra strings are removed,
and missing ones are copied from the primary.
Typically the primary dictionary is in English and secondary for other languages.
If translations are not specified for secondary dictionaries then literals will be copied
from primary dictionary and marked with comment /!TRANSLATE!/.
Also this command synchronizes the changes were made directly in the dictionaries. Here priority is given to
the primary dictionary. If there is no string in the primary, which is in the secondary
dictionary, the string is removed from the secondary dictionary. If the opposite
the string presents in primary but not in secondary, it is copied to the secondary and
labeled with comment /!TRANSLATE!/.
Additional options that affect the work of the command:
-cc,- wc, -q8, -q16 = specify the type of strings.
-remove = removes from the dictionary all the unused string (if you do not write this option, then
these strings are only marked with comment /!REMOVE!/).
-allraw, -allesc, -newraw, -newesc = specify the format of the dictionary file. Options -allraw
and -allesc write all the strings in 'raw' or 'escape' format, respectively; options
-newraw, -newesc do so only with the new strings, maintaining existing in the
current format. The default option is -newesc, that is, the new dictionary
created in the 'escape'-format, but if you use a dictionary in which there
are the strings in 'raw'-format they will remain in the 'raw'.
-level = option, which allows you to run only in part. -level 0
only shows a list of files, not trying to scan them. This can be useful when
you just have a list of project files, preparing, experimenting with different
paths and masks. -level 1 creates a dictionary, but does not modify
the sources. -level 2 (default) also modifies the sources.
If you repent of what did, but forgot make backup, use the command:
gemloc <options> -rollback <prefix> <list of sources> <dictionary file>
This is the twin brother of command -edit, which is trying to rollback things: the names
of the variables replace back to the literals with prefixes, remove the blocks of 'extern'-declarations.
As of command -unmark this command is not meant to replace the backup, because the rollback
is ambiguous.
Summary_____\
Create a module with string variables definitions:
Where <h-file>... is header generated by -loader.
<definitions cpp-file> is a new .cpp file.
When call, use the same <options> that in a command -loader.
Include a new file in the project, along with files
generated in the previous step. Now the program should be successfully
built.
Details____ \
This step is very simple: generate an additional (definition) file, which must be included in the project.
If the loader is one for many libraries, the definition file must be one for each of your
libraries. I am referring to the case when you have for each library a different prefix and a separate
dictionary with a set of strings that are used within the library.
Some of the options the same as those of other commands: options -cc, -wc, -q8, -q16
describe the type of strings, the option -gen
will be needed if you are using a different name for the class loader than the Localizer.
You may specify several .h files. All of them will be added to the .cpp file via #include
directives. In any case there must be file with declaration of loader among those headers.
There are some of specific options. Option -nosplit is purely cosmetic, it prohibits
break the literals in the file, which by default split at newline characters.
And literals appear in the file, if you specify the option -default. Then each string
will be assigned a string from the dictionary at the stage of downloading the program.
What is it for? On the one hand it leads to slight increase in the size of the executable.
But now if the program can not load the dictionary it will still work.
Technically, this allows you to use it without any dictionaries literals in the definition
file will work fine. This can be necessary if you want to use some library withlocalization,
a then without (for some programs, where the localization is not required). For example,
GeMLoc uses the library GWCore, which is localized by GeMLoc. But GeMLoc does not need more
than one language because all programmers understand English, and the possibility to output
to the console in different languages will only make them harder to parse log by scripts
(if they will parse). Therefore, a library GWCore localized using option -default,
and it is used by GeMLoc without dictionary.
It means, including, that you can create and compile several versions, each of which
rigidly built-in literals for specific language.
The option -saveids generates array of string identifiers with name LC_ids or similar.
Localized application itself does not need such identifiers but they may be used for some complex localization processing.
Summary_____\
Create an example by command:
Here <h-file> is header generated by command -loader.
<cpp-file of example> is new .cpp file. When call, use the same <options>
as in a command -loader. Copy from the file lines responsible for
download the dictionary and error handling, paste them in one of the modules
of your program, to load the dictionary during application run-time.
Details____ \
The command will work even if the h-file does not exist yet it require only the name
of the file to insert it into the #include directive.
Сode mentioned above might look like this:
The code might look somewhat differently, if you are using option -gen
Summary_____\
Generate loadable dictionary by command:
Where the first file is created by a command -edit, and the second one must have an
extension .bin or .lng. The resulting file should be specified as argument of the loader.
Details____ \
The options -cc, -wc, -q8, -q16, determine how to save encoded string in the loader file.
If options -wc, -q16, specified then loadable dictionary will contain data converted
from UTF-8 to UTF-16 . Format the loader file can be viewed with command:
This file contains some amount of 4-uint8_t integers, which can have a different uint8_t order.
By default, the uint8_t order for the current architecture used (option -de). Also,
you can force little-endian uint8_t order (option -le), or big-endian (option -be).
Depending on the order of bytes the loadable file will have a signature "LCLR" (little-endian)
or "RLCL" (big-endian). By default, the loader assumed uint8_t order which is normal
in architecture, where the program is running, and if he sees the "wrong" signature file is
considered as incorrect. But if you specify the code generation option -gen Ccs, then
the loader will, if necessary "flip" the 4-uint8_t numbers and download the file correctly.
Additional loadable dictionaries can be obtained from the of secondary dictionaries in the same way
as with the primary dictionary:
Summary_____\
Cpmmand -auto is a macro that executes a few commands
faster than the consecutive calls GeMLoc.
The command has the format:
Commands can be executed: -example, -loader, -edit, -cpp, -bin (in this
order), if they specified enough parameters after <list of source>.
The meaning of the parameters denends on by file extension (from .cpp file refers to
the first command -cpp, the second to a command -loader,
the third to -example.
It is recommended once write a script loc.bat like this:
path\gemloc.exe %$ <options> -auto <prefix> <list of sources> <definitions cpp-file> <loader cpp-file> <loader h-file> <primary dictionary> <secondary dictionary> <secondary dictionary>. .. <loadable dictionary> <loadable dictionary> <loadable dictionary> ...
And daily call only this script:
Details____ \
What commands will be executed depends on the file <file1> <file2> ...
on their extensions:
The order execution of commands:
Options apply to all commands, what can affect. The order of the options is arbitrary.
The option -verbose instructs GeMLoc output to the console a more detailed report.
The option -include instructs GeMLoc insert to begin of generated file content of
other file.
The option -unix instructs GeMLoc to use the symbol '\n' for line endings.
This affects those fragments, which generated by GeMLoc, such as string breaks
in the blocks of 'extern' declarations. Also, it affects to the interpretation of the code '\l'.
The option -dos instructs GeMLoc to use a pair of characters '\r' and '\n' for
line endings. By default, GeMLoc uses string endings native to the system for which is compiled.
The option -regenid, which can only be used with a command -auto,
instructs to re-generate all the string IDs. It may be useful if you've made a lot of manual
changes in the primary dictionary, and string IDs no longer to be similar to the contents
of the strings in the English version.
The option -remdups, which can only be used with a command -auto,
mentioned above excludes from the use of exact duplicates.
They will be marked with the comment /!REMOVE!/ or removed from the dictionary
(with option -remove).
The option -dupidok instructs GeMLoc do not fail with error if found in
dictionary identical entries with the same IDs and content. All such entries
will be treated as single.
The option -nosplit instructs GeMLoc do not split string into several strings.
This is a cosmetic feature that affects the design of dictionaries in the escape-format
and the design of literals in your variable declarations (see command -cpp).
The option -saveids generates array of string identifiers (see command -cpp).
The option -touch shift date of generated file to current date even if generated file
is not changed but dictionary is newer (may be useful for some auto build systems).
Command -help shows help in English.
First, these options specify the type of strings, as mentioned above: -cc, -wc, -q8, q16. In
depending on options loader loads the required data into the required type of string variables.
You may specify several .h files. All of them will be added to the .cpp file via #include
directives. The file to be generated must be last of them.
The remaining options are governed by the code generation option -gen. After -gen without
a space should be set of letters. This set has a first capital letter E, C, N, I, P, which defines the task
(e.g., code generation, error handling), followed by a few more small letters, clarifying the task.
The first task is processing the arguments, which indicate where the loader will get a loadable dictionary.
The code generator provides the following options:
The second task is error handling.
The code generator provides the following options:
The third task is check of data integrity.
The code generator provides the following options:
The fourth task is adjusting names.
The code generator provides the following options:
If you want to specify multiple tasks in an option -gen, then write them all in a single string, but
separately from the options -cc, -wc, -q8, -q16 like this:
The names of string variables are automatically generated from a template:
prefix__hint__suffix
In the dictionary of the same variables mentioned without the first part:
hint__suffix
Here:
The user can change the variable names by searching and replacing them in all files
keeping certain rules:
GeMLoc inserts into the source files to declare variables, such as:
It would be a bad idea to collect all the string variables in a separate header file
because any change would lead to a mass recompilation of all files in which
it is included. The best way (at the cost of editing the source) is insert 'extern'
declarations of individual variables only to those files that use them.
Block of 'extern' declarations will not be inserted into the top of the file because it is
can lead to conflict with the directives #ifndef, the include of precompiled-headers
or "header" comments. GeMLoc skip all the initial comments, directives,
preprocessor and white space, and inserts a block of declarations before the first token of a
different type (the class declaration, body of function, namespace declaration, etc).
For the most of .h/.hpp/.c/.cpp files, this will be the right decision. For exceptions to
the compiler shall issue a syntax error, and you have to to move the block in the editor
to another location in the file. If later GeMLoc find this block in the new place, it will not
move it back, and will make changes in the location you have chosen.
Any localization code for C/C++ involves the replacement of literals to something else.
And if the literal it is by definition constant, then the "something else" will not be a constant
because we can use one language or the other. In GeMLoc constant becomes the string variable
in other localizer may become result returned by the function. Hence, there is a most part of
errors. These errors are not related to the specific localization system, because the cause of them
(using variables in place of the constants) does not depend on the localization system.
The first example: the initialization of static arrays or pointers with literals.
Let us there was before the localization:
After localization GeMLoc:
Some other localization system may use something like:
Static variables are initialized in the undefined order before call the function main.
Therefore, we can not guarantee that the desired dictionary at the time of the
assignment is already loaded, and as a consequence, the variable LC__Hello_world
has the correct string. And in the last example, we do not can guarantee that the
function call will work correctly and 'somefunc' returns the correct value.
Even worse, logic of the program could use of the fact that the variable myString
is loaded with program image before all the constructors, destructors, even
those that relate to static objects.
This will only change the program logic. In the case of GeMLoc you can remove
your definition of variable myString everywhere and use instead a variable LC__Hello_world.
The second example: the initialization of static structures fields with literals.
Let us there was before the localization:
After localization GeMLoc:
Initialization of the structure will occur before the dictionary is loaded,
respectively book1.title will point to the wrong value
(either a blank string or to the English version if you used the option -default).
Recommended correction is to use a double pointer:
- And then everywhere instead of writing book1.title use *book1.title.
The third example: the reliance on specific content or length of the string. For example, your
program relied on the fact that the title of the book above has exactly 10 characters plus
terminator character. Now the program will not work if in another language and another
number of letters. You'll have to determine the actual length with use strlen() or similar functions.
You will also need to replace 'sizeof' with 'strlen'.
Let's say you have a project that you want to split into two, each with a separate
localization. To do this:
Suppose now that you have two projects that you want to unite, including localization.
To do this:
Suppose now that you have two projects, and you want to move a file from one project to another.
You can take advantage of technology integration of projects described above (the moving file will
be used as would be the second project), but sometimes too much duplicate IDs are found and
remove them by hands is hard. Then there are the more smart way.
Suppose the first project Bard uses prefix LSI and dictionaries bard.rus.loc and bard.eng.loc.
The second project GWMM uses prefix LSM and dictionaries gwmm.rus.loc and gwmm.eng.loc.
Specific file to move from Bard to GWMM is recordstream.cpp.
Sometimes it may be advantageous to use integer identifiers for strings.
An example of such a situation: the server generates error messages, and
clients display them. It isn't a good idea to send string from the server
because it has greater size than integer identifiers. In addition clients
may be set to different languages.
For this case, a mechanism of integer identifiers is implemented in GeMLoc.
Literals like "Hello, world!" are converted to variables like
LC__Hello_world, but those variables are not strings but integer.
The use of integer identifiers slows down the process of coding, because
it is not possible postpone GeMLoc launch. Replacement string literals
by integers in most cases will result in a compile error or malfunction code.
GeMLoc must be launched after you finished typing and before start compiling (server-side).
However, this solution still cheaper than the technology involving list
identifiers in a single header file. For integer identifiers GeMLoc
uses a mechanism similar to extern-declarations, and so the addition
of new string and related int-identifier does not lead to a massive
recompilation.
To enable this mechanism use one of the following options:
The localization process is splitted between the client and the server. The server belongs text
dictionaries and source code scanned by GeMLoc. Also the server uses the integer identifiers which
inserted in the source code. The server sends these identifiers to the client. The server should
not include additional files of GeMLoc among the sources or to distributive.
Loadable dictionaries belong to the client and are distributed with the client. All source code,
which is generated by GeMLoc (source and header files of loader, variable declarations, the
example) should be added to the client. The client received an integer identifier
the server and must convert it to a string in the current client language. It's enough to take
dictionary item with an index equal to identifier like this:
Let us touch?
gemloc.exe -auto LC + example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h example.cpp
cl example.cpp strings.cpp loader.cpp
example eng.lng
Translate this first string
Translate this second string
Translate this 3-rd string
Translate this final string
gemloc.exe -auto LC +example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h example.cpp
example eng.lng
example rus.lng
gemloc.exe -auto LC +example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h
=
1. gemloc.exe -example LC example.cpp loader.h
- creates example.cpp
2. gemloc.exe -loader loader.cpp loader.h
- creates and loader.cpp loader.h
3. gemloc.exe -edit LC +example.cpp eng.loc rus.loc
- modifies and creates eng.loc and rus.loc based on strings from example.cpp
4. gemloc.exe -cpp LC eng.loc strings.cpp loader.h
- creates strings.cpp based on eng.loc
5. gemloc.exe -bin eng.loc eng.lng
- creates eng.lng based eng.loc
6. gemloc.exe -bin rus.loc rus.lng
- creates rus.lng based rus.loc
Localization Methods
#define LC
Work Scheme
Magic Prefix
#define LC
LC"Hello, world!"
LC L"Hello, world!"
LC _T("Hello, world!")
LC _TEXT("Hello, world!")
LC("Hello, world!")
LC("Hello, world!", "Здравствуй, мир!")
Localization Type Selection
Commandline Syntax
gemloc [<options>] <command> [<prefix1>] [<prefix2>] [<list of sources>] [<other files>]
gemloc -backup -wc -edit LC +main.cpp +mylib -mylib/*.obj ++external/*.cpp +proj.vcxproj +addon.lst =save.lst english.txt russian.txt
List of Sources
gemloc -backup -wc -edit LC +main.cpp +mylib -mylib/*.obj ++external/*.cpp +proj.vcxproj +addon.lst =save.lst english.txt russian.txt
gemloc -config Debug LC +proj.vcxproj english.txt
Dictionaries
my_string=my string
/!a comment!/
Hello_world=Hello, world!
id=value
hello_world=hello, world,\
i am gemloc-application.
id
value
/END/
E:\GW\Bard\bard_loc.rus.loc: 9 item(s) should be removed.
E:\GW\Bard\bard_loc.rus.loc: 9 item(s) should be translated.
row=row
row=row
row__0=row
row=строка
row__0=ряд
Backup and Recovery
gemloc -backup -edit LC +proj.vcxproj english.txt
gemloc -restore +proj.vcxproj english.txt
gemloc -commit +proj.vcxproj english.txt
Old Project Adaptation
- Place the prefix before literals containing the letters.
- Remove the prefix before the literals.
- Change the prefix before the literals.
Adding a Loader
Sources Modification and Dictionaries Creation
LC"my string" -> LC__my_string
LC"Hello, world!" -> LC__Hello_world
LC L"Hello, world!" -> LC__Hello_world
LC _T("Hello, world!") -> LC__Hello_world
LC _TEXT("Hello, world!") -> LC__Hello_world
LC("Hello, world!") -> LC__Hello_world
/*--LOCALIZER DECLARATIONS-- LC --BEGIN-- */
extern const char
*LC__Hello_world, *LC__my_string, *LC__my_string__0;
/*--LOCALIZER DECLARATIONS-- LC --END-- */
Adding the Variable Definitions
gemloc <options> -cpp <prefix> <dictionary file> <definitions cpp-file> <h-file>
Calling the Loader
gemloc <options> -example <prefix> <cpp-file of example> <h-file>
extern Localizer::Localization LC_info;
static Localizer loader;
bool err = loader.load(argv[1], LC_info);
if (!err)
{
printf ("Error of loading localization from '%s'\n", argv[1]);
return -1;
}
Static instance of this variable is defined in the Veriable Definitions File (see command -cpp).
It is not necessarily static. If you use option -cc, -wc, then the lifetime of the object
should cover the time of use strings, as they are loaded into the "heap" and will be released in destructor
of the object Localizer. And in the case of options -q8, -q16, this object is needed only during
loading and error handling, string after loading stored in static objects such as QString, which are
responsible for the release of heap.
In the example name of the file of loadable dictionary taken from argv[1] but you can
take it from other place because selection of dictionary, prompt the user to select the language,
saving choice are completely up to you.
If you use the option -default, the error can be ignored, but it would be better to report it.
Loadable Dictionary Generation
gemloc <options> -bin <dictionary file> <loadable dictionary>
gemloc -test <loadable dictionary>
Additional Loadable Dictionaries Generation
gemloc <options> -bin <dictionary file> <loadable dictionary>
Daily work with the project
gemloc.exe [<options>] -auto <prefix> <list of sources> <file1> <file2> ...
Other Options and Commands
Format: -include <insert to file> <insert from file>
Appendix 0. Loader Generation Options
IDLOC_ENGLISH_GWSETUP BINARY "gwsetup_loc.eng.bin"
The resource type "BINARY" here is essential, and loadable dictionary file name "gwsetup_loc.eng.bin"
may be different, and the resource ID IDLOC_ENGLISH_GWSETUP may be different.
In .rh file type a line like:
#define IDLOC_ENGLISH_GWSETUP 3007
Give to loader as an input parameter a resource identifier (in this example is IDLOC_ENGLISH_GWSETUP).
gemloc -genIcExscNDictLdr.P__declspec(dllexport). -include loader.cpp my_pch.h -q8 -loader loader.cpp loader.h
Appendix 1. Automatic Generation of Variables Names
Appendix 2. Adding the 'extern' Declarations Blocks
/*--LOCALIZER DECLARATIONS-- LC --BEGIN-- */
extern const char
*LC__Hello_world, *LC__my_string, *LC__my_string__0;
/*--LOCALIZER DECLARATIONS-- LC --END-- */
Appendix 3. Common Errors of Localization
static char myString[] = "Hello, world!";
or
static char *myString = "Hello, world!";
static char myString[] = LC__Hello_world; // here is a compilation error
or
static char *myString = LC__Hello_world; // here may be run-time error
static char myString[] = somefunc("Hello, world!"); // here is a compilation error
or
static char *myString = somefunc("Hello, world!"); // here may be run-time error
struct Book
{
int id;
char *title;
};
static Book book1 = {12, "Tom Sawyer"};
static Book book1 = {12, LC__Tom_Sawyer}; // here may be run-time error
struct Book
{
int id;
char ** title;
};
static Book book1 = {12, &LC__Tom_Sawyer};
Appendix 4. Integration and Splitting of the Projects
Приложение 5. Перенос файлов в другой проект
It will keep in the dictionaries x.rus.loc and y.rus.loc only strings were found in the file recordstream.cpp.
Appendix 6. Localization of client-server applications
static Localizer loader;
loader.load(argv[1], LC_info);
...
printf(loader[integer_id_from_server]);
{kind=link}