GeMLoc - для тех, кто любит быстрый код и быстро кодить
GeMLoc - генератор минимальной локализации (generator of minimum localization). Это утилита для разработчиков программ на C/C++, которая помогает сделать локализацию под разные языки, минимально замедляющую исполнение кода, а сама утилита работает так, чтобы процесс написания кода минимально замедлялся по сравнению с написанием кода без локализации. Идейно утилита представляет собой развитие концепции широко известной библиотеки gettext в сторону ускорения исполнения и написания кода.
Эффективность GeMLoc лучше всего пояснят два примера.

- то есть в процессе написания кода программист печатает перед строкой "волшебный префикс" (в данном примере LC, а можно другой) и... продолжает набивать код дальше, не отвлекаясь на мысли о том, что эту строку надо куда-то скопировать, для нее надо завести идентификатор и т.п. В этом GeMLoc похож на gettext, где программист напечатал бы: _("my string") и продолжил бы писать код дальше, не отвлекаясь. Позднее, в любой удобный день программист запускает скрипт с вызовом GeMLoc, который автоматически выполняет всю "черную" работу, ориентируясь на расставленные префиксы - ищет в программе помеченные строки, заменяет их, вставляет нужные объявления переменных, создает необходимые файлы и т.п.
В числе прочего скрипт сделает такую замену:

- здесь LC__Hello_world - это переменная типа const char * (также допускаются const wchar_t * и QString). То есть, массив const char [] превратился в указатель на char. Здесь нет никакого вызова функции, в которой выполнялся бы поиск по идентификатору, индексу или строке. Была переменная строкового типа - осталась переменная почти того же типа. С GeMLoc можно раз и навсегда забыть о сомнениях: "А не замедлится ли исполнение на большом количестве строк? А не надо ли тут соптимизировать?" Тут оптимизировать не надо - все равно некуда.
GeMLoc имеет много полезных функций. Вот только две для примера: он подсказывает программисту, какие строки больше не нужны (гарантия, что в ресурсах релиза не останется устаревшего мусора), а переводчику подсказывает, сколько строк и на какие языки еще надо перевести.
GeMLoc "дружит" с ASCII, UTF-8, Unicode, Qt, RC, Windows и Unux.
В чем подвох?
Из первоначального описания может показаться, что так хорошо не бывает, должен быть какой-то подвох. Действительно, есть одна трудность, скорее, психологического характера: то, что GeMLoc в процессе работы модифицирует исходники. Страшно? По опыту знаю: некоторым страшно. Поэтому нужны пояснения.
GeMLoc работает с исходниками по принципу "не просят - не лезь". Пока вы сами не поставите перед какой-нибудь строкой тот самый "волшебный префикс", утилита ничего править в этом исходнике не будет.
Вероятность потери данных при записи файла не больше, чем аналогичное несчастье при сохранении исходника в редакторе. При модификации исходника сначала создается временный файл, куда пишется новая версия текста, и только после успешного завершения записи временный файл заменяет существующий (путем переименования). Замена переименованием происходит практически мгновенно, так что порча исходника может произойти разве что из-за сбоя питания, происшедшего именно в эту миллисекунду.
Специально для программистов, которые забывают сохранять данные, GeMLoc имеет несколько команд отката, backup-а и восстановления.
Наконец, надо понять, что именно модифицируется в исходниках. Там не так много на самом деле - всего лишь две вещи. Первая - помеченные "волшебным префиксом" литералы заменяются на имена переменных. Например, вместо LC"Hello, world!" после обработки GeMLoc-ом появится: LC__Hello_world. Второе - эту самую переменную LC__Hello_world надо где-то объявить, поэтому в начале файла после традиционных "комментариев-шапок", #ifdef и #include подыскивается подходящее место, куда вставляется объявление: extern const char * LC__Hello_world;. Вот, собственно, и все - ничего страшного вроде бы. Если интересны подробности, то читайте мануал дальше.
Здесь приведен простой пример, демонстрирующий работу GeMLoc.
GeMLoc может генерировать примеры про самого себя. Заведите какую-нибудь пустую папку
и запустите там GeMLoc с параметрами:
При нормальной работе с локализатором рекомендуется оформить этот вызов в виде .bat-файла
или скрипта, поскольку почти в 100% случаев этого вызова будет достаточно на все случаи жизни.
В папке должно сгенерироваться 8 новых файлов. Что тут что:
Теперь скомпилируйте программу. Для Visual Studio:
Должен получиться example.exe. Запустите его, передав имя загружаемого словаря
через аргумент командной строки:
Программа выведет строки:
Теперь возьмите файл rus.loc. Это - текстовый словарь, с которым должен работать переводчик.
На пометки
/!TRANSLATE!/ пока не обращайте внимания. То, что до знака равенства, не трогайте - это
идентификаторы строк. А вот то, что после, замените на строки другого языка. Внимание!
Для русского языка под Windows используйте кодировку DOS-866, поскольку это консольное приложение.
Теперь опять дайте ту же команду:
А потом:
Программа сначала выведет те же строки на английском, а потом строки, которые вы вписали
в rus.loc - на другом языке (если, конечно, сама консоль настроена правильно - использует
нужную кодировку и шрифт, в котором есть нужные символы).
Теперь посмотрите на содержимое файла example.cpp. Посмотрели? Видите там переменные
вроде LC__Translate_this_first_string? Так выглядят локализованные сроки уже
после локализации.
В данном примере использована команда -auto. Она является основной "рабочей лошадкой"
и по сути представляет собой макрос, который вызывает другие команды. В данном примере
она раскладывается на следующие вызовы:
Советую удалить все созданные файлы и выполнить эти команды, чтобы посмотреть, что происходит на каждом шаге.
Данный раздел я настоятельно рекомендую тем, кто любит задавать вопросы
вроде "а почему сделано так, а не так?", "а зачем это нужно?", "а чем это лучше?"
Если подобные вопросы вас не волнуют, можно раздел пропустить.
Во многих C/C++ проектах возникает необходимость выбирать язык и в зависимости от языка
отображать разные текстовые строки. Со строками, которые загружаются из разных файлов
данных, возни немного: просто создаются варианты этих файлов для каждого языка. Основной
объем работы связан со строками, которые вписаны в исходные тексты в виде так наз.
литералов, проще говоря, в кавычках. Фактически возникает задача, чтобы и эти строки
тоже откуда-то загружались.
Можно, конечно, не использовать литералы вообще, а с самого начала писать программу так,
чтобы все строки загружались извне. Предусмотрительный программист каждый несчастный
"OK", "Yes", "No" оформляет в виде вызова некой функции, которая должна загружать
нужную строку в зависимости от текущего языка, и создает внешние файлы, где содержатся
сами строки хотя бы для одного языка.
Чем хорош такой путь - понятно: программа сразу готова к переводу на разные языки.
Но за это приходится платить более длительным сроком разработки первоначальной версии
продукта. Обычный программист набьет в тексте программы "Yes"
и продолжит бодро печатать код дальше. Предусмотрительный программист напишет что-нибудь вроде
loadString(IDS_YES) потом переключится на файл идентификаторов, где набьет
что-нибудь вроде IDS_YES = 123, потом переключится на файл строк, где набьет
что-нибудь вроде <localization id="IDS_YES" lang="English" value="Yes"/>,
потом вернется к исходному коду. Даже если использовать всякие Copy/Paste,
все равно процесс замедляется из-за необходимости переключаться между файлами.
К тому же, если идентификаторы оформлены в виде заголовочного
файла, который включается во многие исходники, то каждый раз после добавления
новой строки требуется массовая перекомпиляция проекта.
А время идет. Время - деньги работодателя. Жаба давит на мозг работодателя, работодатель
давит на мозг начальнику проекта,
а начальник проекта давит на мозг программистам: мол, сляпайте начальную версию без локализаций,
чтобы было, что показать, локализациями займемся потом. Правильно ли это требование
с точки зрения вселенской справедливости - вопрос, так сказать, философский, вы можете,
конечно, поспорить и потратить на споры еще немного времени (которое - деньги работодателя и
здоровый мозг начальника проекта).
Так или иначе, во многих случаях встает вопрос об оптимизации процесса разработки.
Чтобы понять, что можно улучшить, надо посмотреть, а что у нас есть. Давайте для начала
рассмотрим не одну из продвинутых систем локализации, а то, что программисты часто делают
на скорую руку сами. Типичная система локализации может состоять из 3-4 частей:
Чтобы получить нужную строку, надо как-то указать, которую из строк получать... соответственно
нужен тот самый идентификатор id. В самом худшем случае идентификатор - просто набор цифр,
так сказать "магическое число". Как только программист узнает о вредности "магических чисел", он
заменяет числа на идентификаторы констант - #define, enum или const. Сразу приходит мысль -
выписать все эти константы в едином заголовочном файле.
Так сделано в ресурсных файлах Microsoft. В проекте для Visual Studio обычно есть файл с расширением .rh,
где собираются все целочисленные идентификаторы ресурсов, включая и идентификаторы строк, и есть
файл с расширением .rc, где хранятся сами строки
со ссылками на соответствующие идентификаторы. При компиляции проекта из .rc/.rh
получается файл с расширением .res, который при линковке добавляется к исполняемому файлу .exe.
Во время исполнения программа обращается к загрузчику, который возвращает нужную строку по целочисленному идентификатору.
Мысль вынести все идентификаторы строк в один файл, с одной стороны, правильная:
гарантия, что не будет случайных дубликатов. Но этот заголовочный файл приходится
включать во многие исходники проекта, и малейшее изменение в списке идентификаторов
приводит к массовой перекомпиляции проекта.
Как только программисту надоедают долгие перекомпиляции после каждого "чиха", он начинает
думать: нельзя ли избавиться от заголовочного файла совсем? И возникает естественная мысль - а давайте
идентификаторы будут строками? Следующая мысль - а давайте это будут исходные литералы
на английском? Получается, что при обращении к загрузчику ему дается английская строка;
если текущий язык английский, загрузчик возвращает ту же строку, а если не английский,
он использует эту строку как ключ для поиска перевода на другой язык.
Это и удобно, и наглядно: писать getLocalizedString("Hello, world!") вместо getLocalizedString(IDS_HWRLD)
- сразу ясно, какой текст будет возвращен, и не надо придумывать идентификатор.
Более того, в загрузчике
можно прописать условие, что если подходящей строки нет, вернуть сам идентификатор. Это сразу решает
проблему с переключениями между файлами при наборе исходного кода: можно набивать код, не отвлекаясь,
и все будет работать - правда только на английском, но другие языки можно будет добавить когда-нибудь потом.
Теперь если еще и функцию загрузчика оформить в виде идентификатора минимальной длины
(из одного символа, например, из одного знака подчеркивания), тогда достаточно будет
написать _("Yes") - всего на три символа больше, чем совсем без локализации.
Так получается библиотека gettext и подобные ей.
Все бы хорошо, но программистов старой школы гложут сомнения: они привыкли, что идентификаторы
должны быть по-возможности целыми числами, так как поиск по строке - процесс более медленный.
Его можно оптимизировать, можно при загрузке создать хэш или дерево поиска, но, сколько ни
оптимизируй, это все равно медленнее, чем поиск по целочисленному идентификатору, который может
быть просто индексом в массиве строк.
Программистам новой школы подобные сомнения неведомы - либо совсем, либо до тех пор, пока не
напишут какой-нибудь цикл, где обращение к загрузчику строк происходит много тысяч раз.
Тогда приходится оптимизировать программу. В большинстве случаев это сделать несложно:
обращения к загрузчику выносятся из тел циклов, результаты сохраняются в переменных,
и внутри цикла обращения происходят к этим переменным, без вызова функций.
Ресурсные файлы Microsoft появились в те времена, когда компьютеры были гораздо медленнее,
так что поиск по целому идентификатору казался самым естественным решением. Теперь, когда
мощность техники повысилась, в большинстве случаев годится и относительно медленный поиск по
строке. В большинстве случаев годится - но все же иногда приходится оптимизировать.
Выходит, если сделать локализацию с поиском по целому числу,
тогда будешь тратить время на перекомпиляцию и на переключение между файлами в процессе
набора текста. А если локализация использует поиск по строке, тогда иногда будешь тратить
время на оптимизацию.
И тут оказывается, что есть третий путь, который объединяет достоинства двух предыдущих,
но не наследует их недостатков - тот самый путь, который реализован в GeMLoc.
Этот путь пользуется тем фактом, что в любой программе на C/C++ изначально
уже есть идентификаторы строк - это имена переменных, и есть поиск по идентификаторам
- процесс "линковки" при сборке исполняемого модуля.
На всякий случай уточню термины:
Если я определю строку в одном исходнике
как const char *myString= "Hello, world!", а в другом объявлю ее
как extern const char *myString; и обращусь к ней как myString,
то компилятор найдет эту строку по идентификатору myString и подставит нужный
адрес. Переход на другой язык достигается "переключением" указателя
myString на адрес в памяти, куда зачитана строка для другого языка.
Технологически имеем следующее.
Есть модуль с определениями строк (скажем, somefile.cpp). Под каждую переменную
типа const char* отводится 4 байта (или 8) в области данных для статических
переменных. Далее, есть файл или файлы, в которых содержатся собственно символы строк для разных языков
- словари. Когда выбран язык, то загрузчик выделяет буфер в динамической области памяти (в heap)
и загружает туда символы строк. После этого загрузчик записывает
в переменную типа const char* адрес этого буфера. В других модулях
переменная объявлена как extern. Всякое обращение к переменной будет возвращать текст
на нужном языке.
Пока все хорошо с точки зрения скорости выполнения программы, но остаются переключения между файлами:
вводя строку, надо перейти в файл somefile.cpp, определить там переменную, потом где-то сохранить
литерал для последующей загрузки, потом вернуться в исходный файл, объявить переменную как extern и,
наконец, вписать имя переменной там, где раньше был литерал.
Фокус в том, что все перечисленные действия можно автоматизировать. Для этого заводится некий
"волшебный префикс" - идентификатор из нескольких символов, скажем, LC или LOC.
Чтобы компилятор его игнорировал, этот идентификатор определяется как пустой макрос, то есть:
Далее программист в своем исходнике (скажем, somefile.cpp) пишет: LC"Hello, world!".
Поскольку LC определен как пустой
макрос, то с точки зрения компилятора это все равно, что написать "Hello, world!"
без всяких префиксов. В результате программа скомпилируется как обычно.
Когда будет запущен GeMLoc, он сделает следующее: "придумает" подходящий
идентификатор для переменной, скажем, LC__Hello_world, впишет ее определение как
const char *LC__Hello_world; в файл somefile.cpp,
саму строчку перенесет в файл локализации, а в исходнике somefile.cpp впишет объявление
extern const char *LC__Hello_world; и литерал c префиксом LC"Hello world"
заменит на имя переменной LC__Hello_world. С точки зрения компилятора тип
const char [] заменится на const char *, что в 99% случаев приведет к
успешной перекомпиляции и правильной работе этого исходного файла. В 1% оставшихся
случаев при локализации (любой, не только через GeMLoc) приходится исправлять код
(см. приложение 3).
Вот, собственно, основной принцип. Все остальные возможности GeMLoc связаны с тем,
чтобы реализовать этот принцип максимально удобно.
Этот и все последующие параграфы разделены на две части: "краткую" и "подробную". В "подробной"
части, как говорится, "очень многа букав", зато есть вся сколько-нибудь существенная информация.
В "краткой" части - выжимка. Если вы делаете первые шаги и сразу поняли "краткую" часть,
то "подробную" можно не читать - пока не понадобится выяснить какие-нибудь тонкости.
Кратко____\
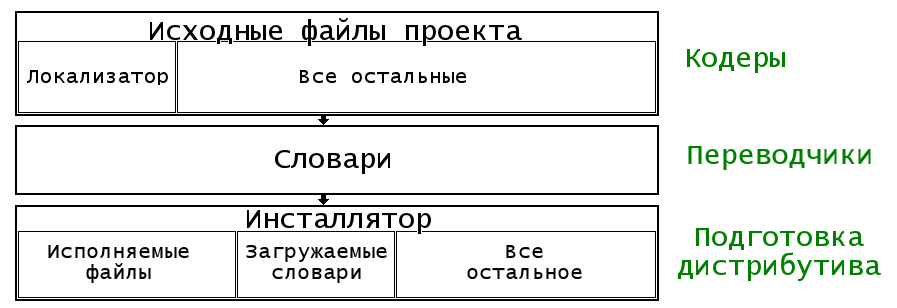
Ниже приведена "крупным планом" схема локализации при помощи GeMLoc.
Подробно____\
Схема предполагает, что над проектом работают три группы разработчиков, каждый отвечает
за свою часть работы. Конечно, в маленьком проекте над всем может трудиться один человек.
Первая группа, обозначенная как "Кодеры", создает собственно программу (или набор программ)
на основе "исходников" - то есть, исходных файлов проекта, куда входят в нашем случае
модули на C/C++ с расширениями .c, .cpp и заголовочные файлы с расширениями .h, .hpp.
К этим файлам GeMLoc добавляет несколько своих файлов, которые создаются и обновляются
в автоматическом режиме. На схеме добавленные файлы обозначены как "Локализатор".
Вторая группа, обозначенная как "Переводчики" занимается переводом словарей на разные языки.
В принципе, этим могут заниматься люди, имеющие весьма отдаленное представление о
программировании - лингвисты, филологи. GeMLoc создает и обновляет словари в автоматическом
режиме и предусматривает для них форматы, удобные для обработки в текстовых редакторах и
понятные неспециалисту.
Третья группа, обозначенная как "Подготовка дистрибутива", занимается написанием инсталлятора.
Для этих разработчиков GeMLoc создает загружаемые словари на основе тех
текстовых словарей, с которыми работали переводчики. Загружаемые словари имеют "нечитабельный"
("двоичный") формат, оптимизированный для быстрой загрузки. Он должны стать частью инсталлированной программы
и будут подгружаться на run-time загрузчиком, код которого входит в прямоугольник "Локализатор"
в верхней части схемы.
Далее вот ссылка на большую и подробную схему, где первая схема
расписана в деталях. Я рекомендую открыть этот рисунок в отдельном окне, периодически обращаясь
к нему в процессе дальнейшего чтения. Позднее той схемы вам может хватить для
напоминания вместо чтения всего этого текста.
Кратко____\
Необходимо выбрать короткий идентификатор (вроде LC), определить его как пустой
#define и пометить им подлежащие
локализации литералы вида "...", L"...", _T("..."), _TEXT("...")
либо спереди в виде префикса LC"...", либо в стиле вызова функции
LC("...").
Подробно____\
Сначала нужно выбрать "волшебный префикс". Это - идентификатор,
который будет отмечать те строки, которые подлежат локализации, а также он
помогает распознать имена, связанные с локализацией и работой GeMLoc.
Для "волшебного префикса" действуют следующие ограничения:
Я рекомендую использовать двухбуквенный префикс LC для основной программы и,
если подключаемые библиотеки имеют отдельные локализации, то для них использовать 3-х
или 4-хбуквенные префиксы вроде LCX, LCZM и т.п. А также, возможно,
вам понравится префикс LK, который проще набивать за счет рядом находящихся клавиш.
Далее, волшебный префикс должен быть определен как пустой макрос, например:
Это определение должно находиться в файле, который включается всюду, где могут
оказаться строки, подлежащие локализации. Естественное решение - добавить это определение
в precompiled header. Префикс, по идее, определяется только один раз и больше
не меняется (или меняется очень редко), так что дополнительными перекомпиляциями это
не грозит.
Теперь нужно использовать волшебный префикс для пометки различных литералов в программе.
Допускается помечать обычные (char) литералы, unicode-литералы (wchar_t), отмеченные префиксом L,
и литералы, обрамленные макросами _T и _TEXT, например:
Обратите внимание, что в первом случае пробел перед строкой необязателен, это немного
экономит вам время "набивания" текста.
Также допускается более длинный формат пометки с применением скобок:
Этот вариант сделан на тот случай, если вы захотите запрограммировать какой-нибудь трюк, определив LC
не как пустой макрос, а как макрос с параметрами или даже функцию.
Также допускается (но не рекомендуется для первоначальной локализации проекта) еще более длинный формат
с указанием переводов на все языки:
Если переводы содержат не ASCII-символы, например, русские буквы, то кодировка "исходника" должна быть
такой, какую вы хотите потом иметь в загруженных строках (рекомендуется UTF-8).
Если вы имеете дело не с только что созданным проектом, а у вас уже есть проект с большим
количеством литералов, расстановка пометок вручную может занять много времени.
GeMLoc может автоматизировать бОльшую часть этой работы, о чем будет рассказано в разделах,
посвященных локализации "старых" проектов.
Кратко____\
Нужно выбрать один из типов локализации: const char * (по умолчанию), const wchar_t*
(опция -wc), или QString (опции -q8/q16, если реализована функция QString::fromUtf8/16 соответственно).
Подробно____\
GeMLoc предоставляет 4 различных типа локализации в зависимости от того, какие
строки вы используете в программе чаще всего.
По-умолчанию предполагается опция -cc, то есть, в загружаемом словаре будут находится данные
типа char, и на них будут указывать переменные типа const char *.
Кодировка символов в данном случае не важна: в какой 8-битной кодировке символы лежат в словаре,
в такой они будут загружены в память. В той же кодировке символы должны быть и в текстовых
словарях, с которыми работают переводчики. В том числе можно использовать UTF-8. В последнем
случае может быть полезна опция -utf8, которая принудительно проверяет, что в словаре
все символы корректны для UTF-8.
Если указать опцию -wc, то текстовый словарь должен быть обязательно в кодировке
UTF-8 (опция -utf8 подразумевается по умолчанию). В загружаемом словаре строки будут
в формате UTF-16 и после загрузки на
них будут указывать переменные типа const wchar_t *. Опция -wc предназначена
только для тех систем, где тип wchar_t - 16-битный, little-endian (как в Windows).
Если вы работаете с библиотекой Qt, вам может показаться удобным использовать строки типа
QString. Тогда текстовый словарь должен быть обязательно в кодировке UTF-8, а
в загружаемом словаре строки будут либо в формате UTF-8, либо в формате UTF-16. Тут все
зависит от варианта Qt, который вы скомпилировали и используете. Проверьте: если
в нем есть функция QString::fromUtf8, то надо использовать UTF-8 и соответствующую
опцию -q8. А если есть функция QString::fromUtf16, используйте
опцию -q16. А если есть и то, и то, поступайте как вам нравится (учтите, что
словари с опцией -q8, скорее всего, будут иметь меньший размер, а словари
с опцией -q16, скорее всего, будут чуть-чуть быстрее загружаться).
В зависимости от метода локализации GeMLoc генерирует подходящий код. Если
разные части программы используют разные виды строк, вы вполне можете
использовать одновременно несколько типов локализации независимо друг от друга.
Чтобы они не смешивались между собой, достаточно использовать разные префиксы.
Вы даже можете применять разные локализации в одном файле, отмечая строки разными
префиксами.
Кратко____\
Все команды GeMLoc имеют единообразный синтаксис:
Подробно____\
Опции всегда начинаются с черточки. Команда присутствует всегда и тоже начинается с черточки.
Есть команды: -auto, -bin, -cpp, -commit, -edit, -example, -help, -loader, -mark,
-prefix, -restore, -rollback, -test, -unmark. Далее может потребоваться
"волшебный префикс", иногда два префикса (всегда без черточек).
Далее идет <список исходников> - аргументы, которые всегда начинаются с символов
-, + или =. Первый аргумент, начинающийся с другого символа, относится
к заключительной части: <другие файлы>.
Например:
Здесь -backup, -wc - опции, -edit - команда, LC - префикс. Далее идет <список исходников>
- это все аргументы, начинающиеся с символов +,- и =. Признаком конца списка исходников является конец списка
аргументов или первый аргумент, начинающийся не с символа +,- и =. Так сделано для единообразия и чтобы не перепутать
нечаянно исходник с другим файлом. В данном примере english.txt и russian.txt - это уже не часть списка,
не исходник, а дополнительные файлы (словари).
Кратко____\
Список исходников формируется серией аргументов:
Подробно____\
Обычный линковщик C/C++ работает не с одним файлом исходников, а со множеством. Список
этих файлов готовится так или иначе в makefile, или сохраняется отдельно как "файл проекта".
GeMLoc также работает с исходниками не по одному, а списками. Это сокращает
время работы утилиты, так как не надо многократно загружать саму программу и
обновлять словари. А главное - это позволяет определить, какие строки уже не
используются в программе.
К исходникам относятся файлы проекта на языке C/C++ - это, как правило, файлы
с расширениями .cpp/.c/.h/.hpp.
Вернемся к примеру:
Здесь список исходников начинается с аргумента +main.cpp и кончается аргументом =save.lst
(включительно).
Все конструкции с плюсом в начале добавляют файлы в список, с минусами - исключают файлы из списка,
с равенством - записывают получившийся список в файл.
Конструкция +main.cpp добавляет в список один файл. В принципе, этим можно было бы и обойтись, но перечислять все файлы
большого проекта - слишком нудно.
Конструкция +mylib добавляет в список все файлы из папки mylib. Но, что, если в этой папке находятся и
исходники, и объектные файлы? Тогда конструкция -mylib/*.obj исключит из уже составленного списка файлы с
расширением .obj, находящиеся в папке mylib. А что, если исходники содержатся не только в заданной папке, но и
в ее подкаталогах? Для этого случая есть конструкция с двумя плюсами: ++external/*.cpp, она говорит GeMLoc
обойти рекурсивно все подкаталоги папки external. Аналогично конструкция с двумя минусами обходит папки рекурсивно,
исключая файлы.
Для программистов, использующих среду Visual Studio, жизнь вообще проста: GeMLoc понимает содержимое файлов проектов
.vcproj и .vcxproj. Достаточно написать +proj.vcxproj, чтобы включить в список все файлы проекта proj.vcxproj.
Более того, если ваш проект для конфигурации Debug включает одни файлы, а для Release - другие
(то есть, часть файлов в зависимости от конфигурации помечена как "Exclude from Build"), вы можете
помещать файлы в список выборочно, указав конфигурацию опцией -config вот так, например:
Замечание: если проект использует относительные пути к файлам, то GeMLoc будет отсчитывать их от папки, где он
взял файл проекта.
Для пользователей других сред разработки может быть полезным подстановка файла, в котором исходники перечислены
списком. В примере выше аргумент +addon.lst подразумевает такой файл. Исходники должны быть перечислены
подряд, по одному в строке. Если пути не абсолютные, они будут отсчитываться от папки, где находится файл со списком.
Наконец, однажды составив список исходников с помощью произвольного набора аргументов, вы сможете записать получившийся
список в файл, чтобы потом подставлять только этот файл. В примере это делает аргумент =save.lst.
Кратко____\
Словарь - центральное понятие в GeMLoc. Бывают текстовые словари (с расширением .txt или .loc)
и загружаемые словари, имеющие двоичный формат и расширение .bin или .lng. По умолчанию под
"словарем" здесь понимается текстовый словарь.
Словари содержат идентификаторы строк и содержимое строк. Также словари могут
содержать комментарии. Например:
Один словарь соответствует одному языку. Словарь для английского как правило "первичный", остальные - "вторичные".
Один первичный и несколько вторичных словарей образуют набор словарей. Один программный продукт может использовать несколько наборов словарей,
например, один для DLL, второй и третий для двух статических библиотек и четвертый
- для основной программы. Очень желательно (во избежание конфликтов имен при линковке)
для разных наборов словарей использовать разные "волшебные префиксы".
Первичный текстовый словарь создается командой -auto или -edit на основе исходников.
Вторичные текстовые словари создаются теми же командами на основе первичного.
Загружаемые словари создаются на основе текстовых командами -auto или -bin.
GeMLoc допускает два формата словарей. Первый - "escape-формат" удобен для программистов,
поскольку применяет привычный синтаксис С/С++ строк с escape-символом '\'. Второй
- "raw-формат" предназначен для лингвистов и филологов, которые не обязаны ничего
знать про escape-коды.
Подробно____\
Escape-формат содержит строки в виде:
id - соответствует имени строковой переменной без префикса. Если переменная называется
LC__Hello_world, то идентификатор в словаре: Hello_world.
value - соответствует содержимому строки. Синтаксис - как у С-литерала, за исключением
следующих моментов:
Как и в строке C/C++ допускается разбивать литералы на несколько строк с \ в конце, например:
Raw-формат содержит строки в виде:
id - такой же идентификатор строки, как в escape-формате.
value - содержимое строки без каких-либо кодов. Переходы на новую строку трактуются как
символы перевода строки за исключением переводов строк после id и перед /END/.
/END/ - индикатор конца строки.
Raw-формат обладает рядом серьезных недостатков: в нем сложно корректно вводить
символы с кодами меньше 32, нереально сохранить различия между '\n' и парой '\r\n',
нельзя использовать последовательность /END/ как часть строки. Поэтому raw-формат
рекомендуется применять только в случае близких контактов любого рода с представителями
дремучей гуманитарщины, которым невозможно объяснить разницу между '\n' и '\r\n'
и которые все время норовят сохранить текстовый файл в формате .doc Microsoft Word.
В данных обстоятельствах придется отдать файл на перевод в формате raw, а потом,
если надо, перевести его в escape-формат и доработать в части специальных символов.
О комментариях
Файл словаря может содержать три коментария на строку:
1. Комментарий /!REMOVE!/ вставляется GeMLoc-ом как индикатор, что данный литерал
не используется в программе. GeMLoc не будет удалять данный литерал, поскольку а)
вы могли просто не упомянуть файл, где литерал все-таки используется и б)
вы могли временно закомментировать кусок кода, где встречается этот литерал. Удалить
неиспользуемые строки из словаря можно либо вручную, либо добавив опцию -remove в команды
-edit или -auto.
Пока в словаре остаются такие комментарии, GeMLoc будет напоминать вам об их существовании
сообщениями вроде:
2. Комментарий /!TRANSLATE!/ вставляется GeMLoc-ом во вторичные словари как индикатор,
что данный литерал был скопирован из первичного словаря. Это - напоминание переводчику о том,
что данная строка - на английском, и ее надо перевести на тот язык, который связан
с этим словарем. Вам нужно будет убирать эти пометки по мере того, как вы переводите строки.
Пока в словаре остаются такие пометки, GeMLoc будет напоминать вам об их существовании
сообщениями вроде:
3. Прочие комментарии вида /!какой-нибудь текст!/ считаются комментариями
пользователя и просто сохраняются как есть.
О дубликатах
Изредка может возникнуть такая ситуация, что какой-то текст в программе должен одинаково выглядеть
на английском, но по-разному - на другом языке. Такая ситуация называется дубликатом.
Обратная ситуация (по-разному на английском, одинаково на другом языке) дубликатом не считается и
не требует специальных действий.
Вы можете создавать дубликаты путем правки первичного словаря в редакторе. Допустим,
у вас есть строка, которая на английском в двух случаях пишется как "row", но на русском
в первом случае как "строка", а во втором - как "ряд". Сканируя файлы с английскими литералами,
GeMLoc создаст в них переменную LC__row, а в словаре одну строку:
Чтобы теперь создать дубликат, надо в том же словаре завести еще одну строку с тем же содержимым, но
другим идентификатором:
Замечание: если идентификатор row__0 уже есть, заведите идентификатор row__1, если и такой
есть, заведите row__2 и т.д.
После этого в русском словаре введите уже разные значения строк:
Если теперь GeMLoc встретит в коде строку LC"row", он предупредит, что не может определить,
какую переменную надо использовать: LC__row или LC__row__0. Вам придется
заменить эту строку на одну из переменных вручную (а extern-декларацию GeMLoc поправит при
следующем вызове сам).
В результате серии подобных правок может создаться ситуация, когда для двух идентификаторов
значения строк совпадают не только для английского, но и для всех прочих языков. Этот случай называется
полным дубликатом. Скорее всего, вы захотите избавиться от лишних копий.
GeMLoc может это сделать автоматически, если вы укажете опцию -remdups в команде -auto.
Тогда вторая из двух одинаковых переменных будет убрана из исходников путем замены на первую,
как следствие перестанет использоваться и будет помечена комментарием /!REMOVE!/. Если одновременно
указать опцию -remove, то она будет сразу удалена из словаря.
О порядке строк
При генерации словарей с целочисленными идентификаторами GeMLoc добавляет
к строковым идентификаторам их целочисленные значения (через запятую). Это сделано для того,
чтобы при добавлении/удалении/изменении строк сохранить большинство целочисленных идентификаторов
прежними и тем самым уменьшить количество изменяемых исходников.
Кратко____\
Серия команд с опцией -backup сохраняет копии всех измененых файлов с расширениями .h.bak, .cpp.bak и т.п.
Первая команда с опцией -backup задает контрольную точку для команды -restore, которая возвращает
все файлы к состоянию перед контрольной точкой. После команды -commit или простого удаления всех
.bak-файлов можно задать новую контрольную точку.
Подробно____\
Для некоторых программистов привычно, что исходники "правит" только человек, а если какие-то исходники создаются
программно, то только программно - человек туда уже не влезает. GeMLoc же вносит мелкие правки в "человеческие"
исходники, и этим может "напрягать" некоторых программистов. Конечно, подобную схему работы использует не один
только GeMLoc - всякие системы автоматического "рефакторинга" занимаются тем же, но упомянутый тип программистов
может опасаться и тех систем тоже. Вместо того, чтобы убеждать их избавляться от паранойи, я предпочел добавить
в GeMLoc возможность автоматического backup-а и восстановления.
Та же возможность будет полезна и для другого типа программистов: которые наоборот действуют слишком рискованно и
начнут экспериментировать с GeMLoc на большом "живом" проекте, не совсем понимая, что они делают и ленясь создать
backup. Для таких тоже будет полезна упомянутая возможность, поскольку она включается добавлением в командную строку
всего одной опции, и уж на это, надеюсь, они свою лень смогут превозмочь. Хотя для совсем-совсем ленивых, в случае
чего, тоже не все будет потеряно, но об этом позже.
Если в любой команде указана опция -backup, то для всякого файла, который GeMLoc попытается изменить, будет сначала создана страховочная
копия с расширением .bak. Например, к файлу main.cpp будет создан файл main.cpp.bak. Обратите внимание: расширение
двойное, чтобы не возникло конфликтов с текстовыми редакторами, которые тоже любят создавать
страховочные файлы, но с одиночным расширением (main.bak).
Пример:
GeMLoc правит исходники по чуть-чуть, но это "чуть-чуть" может произойти за один проход со многими файлами. Откатить
множество мелких правок вручную вполне реально, но зачем возиться, если можно не возиться? Для этого достаточно
добавить в команду опцию -backup. Настоятельно рекомендуется делать это каждый раз, когда вы собираетесь
поставить некий "эксперимент" с GeMLoc-ом, и плохо понимаете, что дальше произойдет.
Если что-то пошло не так, откатить изменения можно командой -restore. В ней надо перечислить все те
же файлы, что и в команде, которая вызвала проблемы. Только уберите аргумент, задающий префикс и опцию -backup:
Это вызов восстановит все измененные файлы из проекта proj.vcxproj и файл english.txt, если он был изменен. При желании,
если задать не все параметры как в прежней команде, можно откатить изменения не во всех файлах, а только в некоторых.
Обратите внимание: -restore - это команда, а -backup - это опция, сопутствующая какой-нибудь команде,
например -edit, -mark или -auto.
Если вы отдаете серию команд с опцией -backup, то GeMLoc действует так, как будто первая команда с этой опцией
задала некую "контрольную точку" (checkpoint), которая отмечает ситуацию, куда надо все откатывать. То есть, после нескольких
команд с опцией -backup одна команда
-restore откатит указанные файлы до того состояния, которое они
имели перед самой первой командой с опцией -backup. Реализовано это просто: если GeMLoc видит, что соответствующий
.bak файл уже существует, он не пытается создать новый.
Это, с одной стороны, удобно: можно долго экспериментировать, не особенно задумываясь о последствиях, отдавая команду
за командой, а потом одной командой все вернуть назад. Но, с другой стороны, если эксперименты закончились успешно, надо
не забыть потом поудалять все эти .bak - файлы, иначе при следующем неудачном эксперименте может произойти откат слишком
далеко назад.
Удалить все .bak файлы можно командой -commit. Она имеет тот же формат, что и -restore:
Если вам покажется, что проще удалить .bak-файлы каким-нибудь файл-менеджером или командой shell-а, то на здоровье:
команда -commit существует, скорее, для полноты и для целей автоматизации.
Чтобы все работало правильно, следуйте принципу: после любых экспериментов с опцией -backup выполните либо
команду -restore, либо команду -commit. Обе они удаляют созданные bak-файлы, только вторая их просто
удаляет, а первая переименовывает на место исходных.
Кратко____\
Подробно____\
При подготовке "старого" проекта к локализации GeMLoc-ом после выбора "волшебного префикса" и составления списка исходников следующим шагом
может быть расстановка префиксов в исходниках. Чтобы ускорить процесс, вы можете сделать это в полуавтоматическом режиме.
Для этого есть команда -mark. Ее формат:
gemloc <опции> -mark <префикс> <список исходников>
Эта команда проставит префиксы перед всеми литералами, которые покажутся GeMLoc-у подходящими
для локализации. Принцип автоматической расстановки следующий:
Автоматическая расстановка не способна угадать точно, что надо локализовать, а что - нет. Поэтому
после нее в любом случае придется выполнить поиск префиксов по всем файлам командой grep,
диалогом Find in Files или аналогичным инструментом. Просмотрите полученный результат и
удалите лишние префиксы. Например, лишним будет локализовать название операционной системы
"Windows", фирмы "Intel" или компьютерную аббревиатуру "HTTP".
По умолчанию префиксы расставляются в форме LC"...". Опция -() говорит
команде использовать вместо этого схему: LC("...").
Если вы не сделали backup, но хотите откатить изменения, попробуйте команду:
gemloc <опции> -unmark <префикс> <список исходников>
Но учтите, что такой откат не всегда взаимно однозначен: в местах, где непосредственно
перед литералами стоят буквы, могут появиться лишние пробелы.
Например, если до маркировки была строка LOGO"aaa", то после маркировки станет:
LOGO LC"aaa", а после снятия пометки станет LOGO "aaa" (с пробелом).
Дело в том, что строка LOGO "aaa" (с пробелом) после маркировки тоже превращается
в LOGO LC"aaa". В общем, команда -unmark и не предназначена для идеального
отката, для этого есть опция -backup.
Если вы решили сменить префикс, используйте команду:
gemloc <опции> -prefix <старый префикс> <новый префикс> <список исходников>
Эта команда сменит префиксы только в помеченных литералах и в переменных, которые были поставлены
на место литералов. После этого надо будет еще изменить соответствующий #define префикса (где вы его
определили), сгенерировать заново определения строк (см. команду -cpp) и поправить имя переменной
при загрузке локализации (см. команду -example).
Кратко____\
Сгенерируйте код загрузчика командой
gemloc <опции> -loader <cpp-файл> <h-файл>
и добавьте два получившихся файла в проект.
Подробно____\
Загрузчик - это модуль, который будет загружать на runtime словари на разных языках.
И хотя самих словарей у нас еще нет, загрузчик стоит сгенерировать заранее, без него
проект потом не скомпилируется. Всего GeMLoc генерирует 4 исходника, из которых 3
обязательно подключаются к проекту. Из них два относятся к загрузчику - один cpp-файл
и один заголовочный h-файл. Если приложение состоит из нескольких библиотек, эти два
файла можно сгенерировать и подключить однократно к одной из библиотек, а из других - вызывать.
Загрузчик выглядит как класс, в котором, не считая конструктора
и деструктора, есть единственная функция load. Имя класса по умолчанию
Localizer, но может быть переопределено.
Загрузчик оформлен именно в виде двух исходников, которые надо добавить в свою программу
или библиотеку, а не в виде готовой библиотеки. Это позволяет использовать один и тот же
исходный код для самых разных компилятров и опций компиляции. Формат команды генерации:
gemloc <опции> -loader <cpp-файл> <h-файл>...
Генератор кода загрузчика предоставляет много разных опций, которые позволяют создать
тот или иной вариант загрузчика. Полный список опций приведен здесь
Кратко____\
Преобразуйте исходники командой:
gemloc <опции> -edit <префикс> <список исходников> <файл первичного словаря> <файл вторичного словаря>
- в результате помеченные "волшебным префиксом" строки будут перенесены в словари,
а на их месте появятся имена строковых переменных.
Подробно____\
Предварительное замечание. Команда -edit важна на этапе обучения, чтобы осваивать процесс
шаг за шагом. В повседневной работе вместо неё рекомендуется команда -auto, которая выполняет
за один раз то, что делают -edit, -cpp и -bin.
-edit - основная команда, которая вносит изменения в исходные файлы.
Первым делом команда сканирует исходники в поисках литералов, помеченных
"волшебным префиксом". Содержимое литералов сохраняется в файлах словарей,
которые должны иметь расширения .txt или .loc. Если словари сохранены успешно,
начинается изменение исходников.
Первое изменение - замена литералов, помеченных "волшебным префиксом", на имена
переменных. Например:
Здесь LC__Hello_world и LC__my_string - строковые переменные типа
const char *, const wchar_t * или QString.
О том, как генерируются имена переменных, см. здесь.
Второе изменение - GeMLoc вставляет блок 'extern'-деклараций для тех переменных,
например:
О том, как выбирается место для вставки блока, см. здесь.
После произведенной замены могут возникнуть ошибки линковки и компиляции. Ошибки
линковки - это нормально, поскольку строковые переменные еще только объявлены
(продекларированы), но не определены. Определения будут добавлены на следующем шаге
(читайте следующий параграф). Что касается ошибок компиляции, то, по идее, они
не должны возникать, если вы подготовили программу к локализации правильно.
Если же нет, читайте разбор наиболее распространенных ошибок здесь.
В приведенных выше примерах указывалась только одна строка для первичного словаря
(как правило, английского). Можно сразу указать все переводы, вот так:
Переводов должно быть столько же, сколько перечислено словарей в команде.
Если переводы содержат не ASCII-символы, например, русские буквы, то
кодировка "исходника" должна быть той, какую вы хотите потом загружать на run-time
(рекомендуется UTF-8).
Сложный синтаксис удобен, если вы хотите добавить только одну строку в давно локализованный проект,
тогда вы немного экономите время на открытие файлов словарей и поиск в них нужной строки.
Более "стандартный" подход заключается в том, чтобы вводить только английский вариант,
а перевод делать позднее, редактируя словари. Этот подход удобнее, когда вы пишете новый модуль
со множеством новых строк, тогда перевод лучше отложить.
Первый словарь - "первичный", остальные - "вторичные". Вторичные словари принудительно
приводятся к тому же набору строк, что и в первичном словаре: лишние строки удаляются,
отсутствующие копируются из первичного.
Как правило, первичный словарь - английский. Остальные - для других языков.
Если для строки не указаны переводы, то английская строка копируется в остальные
словари с пометкой /!TRANSLATE!/.
Также эта команда синхронизирует изменения, сделанные непосредственно в словарях. При этом
приоритет отдается первичному словарю. Если в первичном нет строки, которая есть во вторичном
словаре, то эта строка из вторичного словаря удаляется. Если наоборот в первичном есть
строка, которой нет во вторичном, она копируется во вторичный с пометкой /!TRANSLATE!/.
Дополнительные опции, которые влияют на работу команды:
-cc, -wc, -q8, -q16 = задают тип строк.
-remove = убирает из словарей все неиспользуемые строки (если нет этой опции, то
такие строки только помечаются комментарием /!REMOVE!/).
-allraw, -allesc, -newraw, -newesc = задают формат файла словаря. Опции -allraw
и -allesc записывают все строки в 'raw' или 'escape' формате соответственно; опции
-newraw, -newesc делают это лишь с новыми строками, сохраняя существующие в том
формате, в каком были. По умолчанию используется опция -newesc, то есть, словари
создаются в 'escape'-формате, но если вы подставите словарь в котором есть строки в 'raw'-формате,
они так и останутся в 'raw'.
-level = опция, которая позволяет выполнить команду лишь частично. -level 0
только показывает список файлов, не пытаясь их анализировать. Это может быть полезно, когда
вы только еще готовите список файлов проекта, экспериментируя с разными путями и масками.
-level 1 создает словарь, но не модифицирует исходники. -level 2 (по умолчанию)
еще и модифицирует исходники.
Если вы раскаиваетесь в том, что совершили, но забыли сделать backup, используйте команду:
gemloc <опции> -rollback <префикс> <список исходников> <файл словаря>
Это брат-близнец команды -edit, который пытается вернуть все назад: имена переменных
заменить обратно на литералы, помеченные префиксами, убрать блоки 'extern'-деклараций.
Как и в случае команды -unmark
- эта команда не является полноценной заменой backup, поскольку обратное преобразование
неоднозначно.
Кратко____\
Создайте модуль определений переменных командой:
- где <h-файл> - заголовочный файл загрузчика, сгенерированый командой -loader.
<cpp-файл определений> - новый .cpp файл.
При вызове используйте те же <опции>, что в команде -loader.
Включите новый файл в проект вместе с файлами,
сгенерированными на предыдущем шаге. Теперь программа должна успешно собираться.
Подробно____\
Этот этап очень простой: генерируется дополнительный файл определений, который надо включить в проект.
Если загрузчик может быть один на много библиотек, то файл определений должен быть
для каждой библиотеки свой. Я имею в виду тот случай, когда у вас для каждой библиотеки
свой префикс и отдельный словарь с набором строк, которые используются внутри этой библиотеки.
Часть опций - те же, что у других команд: опции -cc, -wc, -q8, -q16 задают тип строк,
опция -gen понадобится, если вы используете иное имя для класса
загрузчика, чем Localizer.
Можно указать несколько заголовочных файлов, все они будут добавлены в .cpp файл в виде
#include-директив. Какой-то из этих файлов должен содержать декларацию загрузчика.
Есть специфические опции. Опция -nosplit - чисто косметическая, она запрещает
разбивать литералы в файле, которые по умолчанию разбиваются на символах перевода строки.
А сами литералы появятся в файле, если указать опцию -default. Тогда каждой строке
еще на этапе загрузки программы будет присвоена строка из словаря. Что это дает? С одной
стороны - некоторое увеличение размеров исполняемого файла. Но зато теперь если по какой-то
причине программа не сможет загрузить словарь, она все равно будет работать, просто язык
останется тот, что в заданном словаре.
Технически это позволяет вам использовать программу вообще без словарей - "вшитые"
в файл определений литералы будут работать нормально. Это может
понадобиться, если вы хотите использовать какую-то библиотеку то с локализацией, то без нее
- для какой-нибудь программы,
где локализация не требуется. Например, сам GeMLoc использует библиотеку GWCore,
которая локализована GeMLoc-ом. Но GeMLoc-у не нужно несколько языков: все программисты
понимают английский, а возможность вывода в консоль на разных языках только усложнит им
написание скриптов. Поэтому библиотека GWCore локализована с использованием
опции -default, и в GeMLoc используется ее "безсловарная" версия с "вшитыми"
английскими литералами.
Это значит, в том числе,
что вы можете создать и скомпилировать несколько версий программы, в каждой из которых
жестко "зашит" определенный язык.
Опция -saveids дополнительно генерирует массив со строковыми идентификаторами с именем LC_ids (или аналогичным).
Самой локализованной программе они не нужны, но может пригодиться для каких-то сложных алгоритмов, связанных с локализацией.
Кратко____\
Создайте пример командой:
- где <h-файл> - заголовок загрузчика, сгенерированый командой -loader.
<cpp-файл примера> - новый .cpp файл.
При вызове используйте те же <опции>, что в команде -loader.
Скопируйте из нового файла строки, отвечающие за
загрузку словаря и обработку ошибок, поместите их в один из модулей своей программы,
чтобы загружать словарь на этапе запуска приложения.
Подробно____\
Команда сработает, даже если h-файл еще не существует - ей нужно только имя файла,
чтобы вставить его в директиву #include.
Упомянутый код, который надо скопировать, может выглядеть так:
Код может выглядеть несколько иначе, если вы при помощи
опции -gen модифицировали загрузчик по умолчанию.
Важно, что в коде должно быть:
Кратко____\
Создайте загрузочный словарь командой:
- где первый файл создается командой -edit, а второй должен иметь расширение
.bin или .lng. Полученный файл надо отдать на вход загрузчику.
Подробно____\
Из опций, имеют значение опции -cc, -wc, -q8, -q16, от которых зависит,
в какой кодировке сохранять строки в загрузочном файле. Если -wc или -q16, то происходит конверсия из UTF-8 в UTF-16.
Формат загрузочного файла можно посмотреть командой:
В этом файле есть некоторое количество 4-байтовых чисел, в которых может быть разный порядок байт.
По-умолчанию используется порядок байт для текущей архитектуры (опция -de). Также порядок байт
можно установить принудительно: little-endian (опция -le) или big-endian (опция -be).
В зависимости от порядка байт загрузочный словарь будет иметь сигнатуру "LCLR" (little-endian)
или "RLCL" (big-endian). По-умолчанию загрузчик расчитывает на тот порядок байт, который действует
на архитектуре, где запущена программа и если видит "не ту" сигнатуру, считает файл испорченным.
Но если при генерации кода вы укажете опцию -gen Ccs, то загрузчик будет при необходимости
"переворачивать" 4-байтовые числа, и загрузит такой файл корректно.
Дополнительные загрузочные словари получаются из вторичных словарей точно так же,
как из первичного словаря:
Кратко____\
Команда -auto представляет собой макрокоманду, которая выполняет несколько команд
с более высокой скоростью, чем несколько последовательных вызовов GeMLoc.
Команда имеет формат:
Могут быть выполнены команды -example, -loader, -edit, -cpp, -bin (в таком
порядке), если для них указано достаточно параметров после <списка исходников>.
Смысл параметров распознается по расширениям файлов (из .cpp файлов первый относится к команде
-cpp, второй - к команде -loader, третий - к -example.
Рекомендуется один раз создать скрипт loc.bat такого вида:
путь\gemloc.exe %$ <опции> -auto <префикс> <список исходников> <cpp-файл определений> <cpp-файл загрузчика> <h-файл загрузчика> <первичный словарь> <вторичный словарь> <вторичный словарь>... <загружаемый словарь> <загружаемый словарь> <загружаемый словарь>...
- и в процессе работы вызывать только его:
Подробно____\
Какие команды будут выполнены, зависит от файлов <файл1> <файл2>... Как
понимаются эти файлы, зависит от их расширений:
Порядок исполнения команд:
Опции влияют на все команды, на какие могут повлиять.
Порядок перечисления опций - произвольный.
Опция -verbose инструктирует GeMLoc выводить в консоль более подробный отчет.
Опция -include инструктирует GeMLoc вставить в начало генерируемого файла
содержимое другого файла.
Опция -unix инструктирует GeMLoc использовать символ '\n' для окончаний строк.
Это влияет на те фрагменты, которые генерирует сам GeMLoc, например, на переводы строк
в блоках 'extern'-объявлений. Также это влияет на интерпретацию кода '\l'.
Опция -dos инструктирует GeMLoc использовать пару символов '\r' и '\n' для окончаний строк.
По умолчанию GeMLoc использует окончания строк, "родные" для системы, для которой он скомпилирован.
Опция -regenid, которая может использоваться только с командой -auto,
вызывает всеобщую пере-генерацию идентификаторов строк. Может быть полезно, если
вы внесли много ручных правок в первичный словарь, и идентификаторы строк перестали
быть похожими на содержимое строк в английском варианте.
Опция -remdups, которая может использоваться только с командой -auto,
упоминалась выше - она исключает из использования полные дубликаты.
Если также есть опция -remove, дубликаты будут удалены, иначе - только помечены для удаления.
Опция -dupidok указывает при загрузке словарей не трактовать как ошибку одинаковые
строки (в которых совпадают как идентификаторы строк, так и их содержимое). При этом
все такие строки трактуются как одна.
Опция -nosplit инструктирует GeMLoc не разбивать длинные строки на несколько.
Это чисто косметическая опция, которая влияет на оформление словарей в escape-формате
и на оформление литералов в файле объявлений переменных (см. команду -cpp).
Опция -saveids дополнительно генерирует массив со строковыми идентификаторами (см. команду -cpp).
Опция -touch сдвигает даты генерируемого файла, даже если он
не изменился, но файл словаря новее (полезно для систем сборки, ориентирующихся на даты).
Команда -help показывает подсказку на английском языке.
Во-первых, это опции, задающие тип строк, о которых говорилось выше: -cc, -wc, -q8
и -q16. В
зависимости от них загрузчик загрузит нужные данные в строковые переменные нужного типа.
Можно указать несколько заголовочных файлов, все они будут добавлены в .cpp файл в виде
#include-директив. Последний из них - тот, который будет сгенерирован.
Оставшиеся варианты генерации кода регулируются опцией -gen. После -gen без пробела
идет набор букв. В этом наборе сначала идет большая буква E, C, N, I, P, которая определяет задачу
(например, генерацию кода, выполняющего обработку ошибок), а следом - еще несколько букв,
уточняющих задачу.
Первая задача - обработка входных данных, которые указывают, откуда загрузчик получит сам словарь.
Генератор кода предусматривает следующие варианты:
Вторая задача - обработка ошибок.
Генератор кода предусматривает следующие варианты:
Третья задача - проверка целостности данных.
Генератор кода предусматривает следующие варианты:
Четвертая задача - согласование имен.
Генератор кода предусматривает следующие опции:
Если вы хотите указать несколько задач в опции -gen, то пишите их все подряд, но
отдельно от опций -cc, -wc, -q8, -q16 вот так:
Имена строковых переменных генерируются автоматически по шаблону:
префикс__подсказка__суффикс
В словаре те же переменные упоминаются без первой части:
подсказка__суффикс
Здесь:
Пользователь может изменять имена переменных путем поиска и замены их во всех файлах,
соблюдая определенные правила:
GeMLoc вставляет в исходные файлы объявления переменных, например:
Это была бы плохая идея - собрать все строковые переменные в отдельный заголовочный файл,
потому что любые изменения привели бы к массовой перекомпиляции всех файлов, в которых
он включен. Лучший способ (ценой правки исходников) - вставить 'extern' объявления
отдельных переменных только в те файлы, которые их используют.
Блок 'extern' деклараций не будет вставлен в начало файла, потому что это
может привести к конфликтам с директивами #ifndef, включением precompiled-заголовков
или "шапкой" комментариев. GeMLoc пропускает все первоначальные комментарии, директивы
препроцессора и пустые сроки и вставляет свой блок деклараций перед первой лексемой иного типа:
объявлением класса, телом функции, объявлением пространства имен и т.д. Для подавляющего
большинства .h/.hpp/.c/.cpp файлов это будет правильное решение. Для исключений компилятор
должен выдать синтаксическую ошибку, и вам надо будет в редакторе передвинуть блок деклараций
на другое место в файле. Если в дальнейшем GeMLoc найдет этот блок на новом месте, он не будет
перемещать его обратно, а будет вносить в него изменения в том месте, которое вы выбрали.
Любая локализация кода для C/C++ подразумевает замену литералов на что-то другое.
И, если литералы - это по определению константы, то "что-то другое" константой уже
не будет - ведь мы можем загрузить один язык, а можем и другой. Соответственно там,
где была константа, будет переменная величина: в GeMLoc - значение переменной, в других
локализаторах - переменный результат, возвращенный функцией. Отсюда и происходит значительная часть
ошибок. Ошибки эти не связаны с конкретной системой локализации, поскольку причина их -
использование переменных величин на месте констант - не зависит от системы локализации.
Первый пример - инициализация статических массивов или указателей литералами.
Пусть перед локализацией было:
После локализации GeMLoc:
Для системы локализации, использующей функции, будет что-то типа:
Статические переменные инициализируются в неопределенном порядке перед
вызовом функции main. Поэтому мы не можем гарантировать, что нужный
словарь к моменту присваивания уже загружен и, как следствие, в переменной
LC__Hello_world лежит правильная строка. А в самом последнем примере мы не
можем гарантировать, что вызов функции somefunc сработает правильно и
вернет правильное значение. Хуже того: ранее логика программы могла
использовать тот факт, что переменная myString загружается вместе с
бинарным образом программы раньше всех конструкторов-деструкторов, даже
тех, что относятся к статическим объектам.
Здесь поможет только изменение в логике программы. В случае GeMLoc
можно убрать объявление переменной myString совсем и везде вместо нее
использовать переменную LC__Hello_world.
Второй пример - инициализация полей статических структур литералами.
Пусть перед локализацией было:
После локализации GeMLoc:
Инициализация структуры произойдет до того, как будет загружен словарь,
соответственно book1.title будет смотреть на значение переменной
до загрузки - то есть либо на пустую строку, либо на английскую версию
(если использована опция -default). Рекомендуемый выход -
использовать двойной указатель:
- и далее везде вместо book1.title писать *book1.title.
Третий пример - расчет на конкретное содержимое или длину строки. Допустим, ваша
программа расчитывала на то, что в названии книги выше ровно 10 символов плюс
концевой ноль. Теперь программа работать не будет, если на другом языке другое
число букв. Придется везде для определения фактической длины использовать
strlen() или аналогичные функции. Также придется заменить sizeof на strlen.
Допустим, у вас есть проект, который вы хотите разделить на два, имея в каждом отдельную
локализацию. Для этого:
Допустим теперь, что у вас есть два проекта, которые вы хотите объединить, в том числе объединить и локализации.
Для этого:
Допустим, у вас есть два проекта, и вы хотите перенести файл из одного проекта в другой.
Можно воспользоваться технологией слияния проектов, описанной выше (перенесенные файлы будут
как бы вторым проектом), но иногда образуется слишком много неполных дубликатов, и убирать их
вручную тяжело. Тогда есть более хитрый путь.
Пусть один проект Bard использует префикс LSI, и в нем есть словари bard.rus.loc и bard.eng.loc.
Второй проект GWMM использует префикс LSM, и в нем есть словари gwmm.rus.loc и gwmm.eng.loc.
Конкретный файл, подлежащий переносу из Bard в GWMM пусть будет recordstream.cpp.
Иногда может быть выгодно использовать целочисленные идентификаторы строк.
Пример такой ситуации: сервер генерирует сообщения об ошибках, а клиенты должны их
отображать. Передавать строки с сервера - не очень удачная идея, поскольку строки
"весят" больше, чем целочисленные идентификаторы. Кроме того клиенты могут быть
настроены на разные языки.
На этот случай в GeMLoc реализован механизм целочисленных идентификаторов строк.
Литералы вроде "Hello, world!" превращаются
в переменные вроде LC__Hello_world, но эти переменные не строковые, а
целочисленные.
Применение целочисленных идентификаторов замедляет процесс написания кода, так как
уже нельзя откладывать запуск GeMLoc "на потом" - ведь замена строковых литералов
на int-ы в большинстве случаев приведет к ошибкам компиляции или неправильной работе кода.
GeMLoc должен быть запущен до того, как начнется компиляция, чтобы (на стороне сервера)
превратить литералы в int-ы.
Тем не менее, такое решение все-таки дешевле, чем технологии, предполагающие хранение
идентификаторов в едином заголовочном файле. Для целочисленных идентификаторов GeMLoc
использует механизм, аналогичный extern-объявлениям, и поэтому появление новых строк
и соответствующих int-идентификаторов не ведет к "глобальной" перекомпиляции.
Для включения этого механизма необходимо добавить одну из опций:
Процесс локализации разделяется между клиентом и сервером. Серверу принадлежат текстовые словари
и исходники, которые сканирует GeMLoc. Также сервер использует целочисленные идентификаторы, которые
вставляются в исходники. Сервер пересылает эти идентификаторы клиенту. Сервер не должен включать в
себя какие-либо дополнительные файлы - в исходниках или дистрибутиве.
Загружаемые словари принадлежат клиенту и поставляются с дистрибутивом клиента. Все исходники,
которые генерирует GeMLoc (код и заголовочный файл загрузчика, объявления переменных, код,
вызывающий загрузчик) должны быть добавлены в клиент. Клиент, получив целочисленный идентификатор
от сервера, должен преобразовать его в строку на текущем языке клиента. Для этого достаточно взять
элемент словаря с индексом, равным идентификатору:
Пощупаем?
gemloc.exe -auto LC +example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h example.cpp
cl example.cpp strings.cpp loader.cpp
example eng.lng
Translate this first string
Translate this second string
Translate this 3-rd string
Translate this final string
gemloc.exe -auto LC +example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h example.cpp
example eng.lng
example rus.lng
gemloc.exe -auto LC +example.cpp eng.loc rus.loc eng.lng rus.lng strings.cpp loader.cpp loader.h
равно:
1. gemloc.exe -example LC example.cpp loader.h
- создает example.cpp
2. gemloc.exe -loader loader.cpp loader.h
- создает loader.cpp и loader.h
3. gemloc.exe -edit LC +example.cpp eng.loc rus.loc
- модифицирует example.cpp и создает eng.loc и rus.loc на основе строк из example.cpp
4. gemloc.exe -cpp LC eng.loc strings.cpp loader.h
- создает strings.cpp на основе eng.loc
5. gemloc.exe -bin eng.loc eng.lng
- создает eng.lng на основе eng.loc
6. gemloc.exe -bin rus.loc rus.lng
- создает rus.lng на основе rus.loc
Способы локализации текста
#define LC
Схема работы
Волшебный префикс
#define LC
LC"Hello, world!"
LC L"Hello, world!"
LC _T("Hello, world!")
LC _TEXT("Hello, world!")
LC("Hello, world!")
LC("Hello, world!", "Здравствуй, мир!")
Выбор типа локализации
Формат команд GeMLoc
gemloc [<опции>] <команда> [<префикс1>] [<префикс2>] [<список исходников>] [<другие файлы>]
gemloc -backup -wc -edit LC +main.cpp +mylib -mylib/*.obj ++external/*.cpp +proj.vcxproj +addon.lst =save.lst english.txt russian.txt
Списки исходников
gemloc -backup -wc -edit LC +main.cpp +mylib -mylib/*.obj ++external/*.cpp +proj.vcxproj +addon.lst =save.lst english.txt russian.txt
gemloc -config Debug LC +proj.vcxproj english.txt
Словари
my_string=my string
/!какой-то комментарий!/
Hello_world=Hello, world!
id=value
hello_world=hello, world, \
i am gemloc-application.
id
value
/END/
E:\GW\Bard\bard_loc.rus.loc: 9 item(s) should be removed.
E:\GW\Bard\bard_loc.rus.loc: 9 item(s) should be translated.
row=row
row=row
row__0=row
row=строка
row__0=ряд
Безопасность и backup
gemloc -backup -edit LC +proj.vcxproj english.txt
gemloc -restore +proj.vcxproj english.txt
gemloc -commit +proj.vcxproj english.txt
Подготовка "старого" проекта
- расставить префиксы перед литералами, содержащими буквы.
- убрать префиксы перед литералами.
- сменить префиксы перед литералами.
Добавление загрузчика
Модификация исходников
LC"my string" -> LC__my_string
LC"Hello, world!" -> LC__Hello_world
LC L"Hello, world!" -> LC__Hello_world
LC _T("Hello, world!") -> LC__Hello_world
LC _TEXT("Hello, world!") -> LC__Hello_world
LC("Hello, world!") -> LC__Hello_world
/*--LOCALIZER DECLARATIONS-- LC --BEGIN--*/
extern const char
*LC__Hello_world, *LC__my_string, *LC__my_string__0;
/*--LOCALIZER DECLARATIONS-- LC --END--*/
LC("Hello, world!", "Здравствуй, мир!")
Генерация определений переменных
gemloc <опции> -cpp <префикс> <файл словаря> <cpp-файл определений> <h-файл>
Вызов загрузчика
gemloc <опции> -example <префикс> <cpp-файл примера> <h-файл>
extern Localizer::Localization LC_info;
static Localizer loader;
bool err= loader.load(argv[1], LC_info);
if (!err)
{
printf("Error of loading localization from '%s'\n", argv[1]);
return -1;
}
Статический экземпляр этой переменной определен в файле определений строк (см. команду -cpp).
Необязательно static. Если используются опции -cc, -wc, то время жизни объекта
должно перекрывать время использования загруженных строк, т.к. они загружаются в "кучу"
и освобождаются с уничтожением объекта Localizer. А в случае применения опций
-q8, -q16 этот объект нужен только на время загрузки и обработки ошибок, после загрузки строки
хранятся в статических объектах типа QString, которые сами отвечают за освобождение "кучи".
Необязательно имя файла загружаемого словаря брать из argv[1] - какие словари загружать, как и когда предлагать пользователю выбрать язык, где запоминать выбор - это все полностью на ваше усмотрение.
Если используете опцию -default, ошибки можно игнорировать, но было бы лучше о них сообщать.
Подготовка загрузочного словаря
gemloc <опции> -bin <файл словаря> <загрузочный файл словаря>
gemloc -test <загрузочный файл словаря>
Создание дополнительных загрузочных словарей
gemloc <опции> -bin <файл словаря> <загрузочный файл словаря>
Повседневная работа с проектом
gemloc.exe [<опции>] -auto <префикс> <список исходников> <файл1> <файл2>...
Другие опции и команды
Формат: -include <в какой файл вставлять> <какой файл вставлять>
Приложение 0. Опции генерации загрузчика
IDLOC_ENGLISH_GWSETUP BINARY "gwsetup_loc.eng.bin"
Тип ресурса "BINARY" тут существенен, а имя файла загружаемого словаря "gwsetup_loc.eng.bin"
может быть другим и идентификатор ресурса IDLOC_ENGLISH_GWSETUP может быть другим.
В .rh файл впишите строку вроде:
#define IDLOC_ENGLISH_GWSETUP 3007
Загрузчику в качестве входного параметра надо будет передать идентификатор ресурса
(в данном примере - IDLOC_ENGLISH_GWSETUP).
gemloc -genIcExscNDictLdr.P__declspec(dllexport). -include loader.cpp my_pch.h -q8 -loader loader.cpp loader.h
Приложение 1. Автоматическая генерация имен переменных
Приложение 2. Вставка блока 'extern' деклараций
/*--LOCALIZER DECLARATIONS-- LC --BEGIN--*/
extern const char
*LC__Hello_world, *LC__my_string, *LC__my_string__0;
/*--LOCALIZER DECLARATIONS-- LC --END--*/
Приложение 3. Распространенные ошибки локализации
static char myString[]= "Hello, world!";
или
static char *myString= "Hello, world!";
static char myString[]= LC__Hello_world; //здесь будет ошибка компиляции
или
static char *myString= LC__Hello_world; //здесь возможна ошибка исполнения
static char myString[]= somefunc("Hello, world!"); //здесь будет ошибка компиляции
или
static char *myString= somefunc("Hello, world!"); //здесь возможна ошибка исполнения
struct Book
{
int id;
char *title;
};
static Book book1 = {12, "Tom Sawyer" };
static Book book1 = {12, LC__Tom_Sawyer }; //здесь возможна ошибка исполнения
struct Book
{
int id;
char **title;
};
static Book book1 = {12, &LC__Tom_Sawyer };
Приложение 4. Объединение и разделение проектов
Приложение 5. Перенос файлов в другой проект
Она оставит в словарях x.rus.loc и y.rus.loc только те строки, которые найдены в файле recordstream.cpp.
Приложение 6. Локализация клиент-серверных приложений
static Localizer loader;
loader.load(argv[1], LC_info);
...
printf(loader[integer_id_from_server]);
{kind=link}